Директива #error
С помощью этой директивы можно вывести сообщение об ошибке при компиляции.
#error сообщение
Сообщение представляет собой любую строку (не заключенную в кавычки!), которая может содержать макросы, расширяемые препроцессором. Обычно директива применяется, чтобы обеспечить определение некоторого идентификатора:
#ifndef WIN_VERSION
terror He определена версия Windows!
#endif
Директива # include
Об этой директиве мы уже достаточно говорили в прошлой главе. Напомним вкратце, что препроцессор заменяет директиву содержимым указанного в ней файла. Есть две ее формы:
#include <filename> #include "filename"
В первом случае поиск нужного файла производится только в стандартных каталогах включаемых файлов; во втором случае этому предшествует поиск в текущем каталоге.
Директива # linе
Директива позволяет установить внутренний счетчик строк компилятора, возвращаемый макросом _LINE_. Она имеет следующий вид:
#line номер строки ["имя файла"]
Номер_строки должен быть целой константой. Если указано необязательное имя_файла, то модифицируется также значение макроса_FILE_.
Директива # pragma
Эта директива служит для установки параметров, специфичных для компилятора. Часто выполняемые с ее помощью установки можно выполнить и другим способом, например, в диалоге Project Options или в командной строке компилятора. Директива имеет вид
#pragma директива
Что такое директива, описывает следующая таблица.
Таблица 4.3. Директивы “pragma компилятора C++Builder
| Директива |
Описание |
||
| alignment | Выдает сообщение о текущем выравнивании данных и размере enum-типов. | ||
| anon struct | Синтаксис:
#pragma anon struct on ^pragma anon struct off Разрешает или запрещает использование вложенных анонимных структур в классах. | ||
| argsused | Подавляет выдачу сообщения о неиспользуемых параметрах для функции, непосредственно следующей за директивой. | ||
| checkoption | Синтаксис:
#pragma checkoption строкаопций Проверяет, установлены ли опции, указанные в директиве. Если нет, выдается сообщение об ошибке. | ||
| codeseg | Синтаксис:
#pragma codeseg [имясегмента] ["класс"] [группа] Позволяет указать имя или класс сегмента либо группу, где будут размещаться функции. Если все опции директивы опущены, используется сегмент кода по умолчанию. | ||
| comment | Записывает строку-комментарий в объектный или исполняемый файл. Синтаксис:
ftpragma comment (тип, "строка") | ||
| exit | Позволяет указать функцию (функции), которая будет вызываться непосредственно перед завершением программы. Синтаксис директивы:
#pragma exit имя функции [приоритет] Необязательный приоритет в диапазоне 64-255 определяет порядок вызова подобных функций (чем он выше, т. е. меньше, тем позже вызывается функция). | ||
| hdrfile | Специфицирует имя файла прекомпилируемых заголовков. | ||
| hdrstop | Запрещает включать дальнейшую информацию в файл прекомпилируемых заголовков. | ||
| inline | Говорит компилятору, что файл должен компилироваться через ассемблер (компилятор генерирует код ассемблера, затем запускает TASM, который выдает конечный obj-файл). | ||
| intrinsic | Синтаксис:
#pragma intrinsic [-]имяфункции Управляет inline-расширением внутренних (intrinsic) функций (к ним относятся в основном функции исполнительной библиотеки для работы со строками, такие, как strncpy, memset и другие). | ||
| link | Синтаксис:
#pragma link "имяфайла" Заставляет компоновщик подключить к исполняемому модулю указанный объектный файл. | ||
| message | Синтаксис:
#pragma message ("текст"...) ttpragma message текст Выдает сообщение при компиляции. | ||
| nopushoptwarn | Подавляет предупреждение о том, что опции компилятора, имевшиеся в начале обработки текущего "файла, не были восстановлены к концу его компиляции (см. ниже о #pragma option). | ||
| obsolete | Синтаксис:
#pragma obsolete имяфункции Выдает предупреждение о том, что данная функция является устаревшей (если имеются обращения к ней). Директивой можно информировать других программистов, что вы усовершенствовали свой код и предусмотрели новую функцию для данной задачи. | ||
| option | Синтаксис:
#pragma option опции #pragma option push опции #pragma option pop Директива позволяет указать необходимые опции командной строки прямо в коде программы. Форма option push сначала сохраняет текущие установки в стеке компилятора; option pop, соответственно, выталкивает из стека последний набор опций. | ||
| pack | Синтаксис:
#pragma pack(n) #pragma pack (push, n) #pragma pack(pop) Задает выравнивание данных в памяти и эквивалентна ftpragma option -an. | ||
| package | Синтаксис:
#pragma package(smart init) #pragma package(smart init, weak) Управляет порядком инициализации модулей в пакетах C++Builder; по умолчанию включается в начало каждого автоматически создаваемого модуля. | ||
| resource | Синтаксис:
tpragma resource "*.dfm" Текущий файл помечается как модуль формы; в текущем каталоге должны присутствовать соответствующий dfrn-файл и заголовок. Всеми этими файлами IDE управляет автоматически. | ||
| startup | Аналогична pragma exit; позволяет специфицировать функции, исполняющиеся при запуске программы (перед вызовом main). Функции с более высоким приоритетом вызываются раньше. | ||
| warn | Позволяет управлять выдачей предупреждений. Синтаксис:
#pragma warn +|-\.www Www может быть трехбуквенным или четырехзначным цифровым идентификатором конкретного сообщения. Предшествующий ему плюс разрешает выдачу предупреждения, минус запрещает, точка — восстанавливает исходное состояние. |
О различных ключах командной строки (и эквивалентных установках диалога Project Options) мы расскажем в разделе об особенностях компилятора.
Директивы препроцессора
Препроцессорная обработка представляет собой первую фазу того процесса, что именуется компиляцией программы на C/C++. Компилятор C++Builder не генерирует промежуточного файла после препроцессорной обработки. Однако, если хотите, можно посмотреть на результат работы препроцессора, запустив отдельную программу срр32.ехе из командной строки:
срр32 myfile.c
Макроопределения
Макроопределения, называемые в просторечии макросами, определяются директивой препроцессора #define. Можно выделить три формы макросов #define: простое определение символа, определение символической константы и определение макроса с параметрами.
Простое определение выглядит так:
#define NDEBUG
После такой директивы символ NDEBUG считается определенным. Не предполагается, что он что-то означает; он просто — определен (как пустой). Можно было бы написать:
#define NDEBUG 1
Тогда NDEBUG можно было бы использовать и в качестве символической константы, о которых говорилось в предыдущей главе. Всякое вхождение в текст лексемы NDEBUG препроцессор заменил бы на “I”. Зачем нужны макроопределения, которые ничего не определяют, выяснится при обсуждении условных конструкций препроцессора.
Как вы могли бы догадаться, #define может определять не только константы. Поскольку препроцессор выполняет просто текстовую подстановку, можно сопоставить символу и любую последовательность операторов, как показано ниже:
#define SHUTDOWN \
printf("Error!"); \ return -1
…
if (ErrorCondition()) SHUTDOWN; // "Вызов" макроса.
Обратная дробная черта (\) означает, что макрос продолжается на следующей строчке. В отличие от операторов С директивы препроцессора должны располагаться в одной строке, и поскольку это технически не всегда возможно, приходится явно вводить некоторый признак продолжения.
Определенный ранее макрос можно аннулировать директивой #undef:
#undef NDEBUG
После этого макрос становится неопределенным, и последующие ссылки на него будут приводить к ошибке при компиляции.
Предопределенные макросы
Компилятор C++Builder автоматически определяет некоторые макросы. Их можно разбить на две категории: макросы ANSI и макросы, специфические для C++Builder. Сводки предопределенных макросов даны соответственно в таблицах 4.1 и 4.2.
Таблица 4.1. Предопределенные макросы ANSI
| Макрос |
Описание |
||
| DATE | Литеральная строка в формате “mmm dd yyyy”, представляющая дату обработки данного файла препроцессором. | ||
| FILE | Строка имени текущего файла (в кавычках). | ||
| LIME | Целое, представляющее номер строки текущего файла. | ||
| STDC | Равно 1, если установлена совместимость компилятора со стандартом ANSI (ключ -А командной строки). В противном случае макрос не определен. | ||
| TIME | Строка в формате “hh:mm:ss”, представляющее время препроцессорной обработки файла. |

Значения макросов _file_ и _line_ могут быть изменены директивой #line (см. далее).
Таблица 4.2. Предопределенные макросы C++Builder
|
Макрос |
Значение |
Описание |
| ВСОРТ | 1 | Определен в любом оптимизирующем компиляторе. |
| BCPLUSPLUS | 0х0540 | Определен, если компиляция производится в режиме C++. В последующих версиях будет увеличиваться. |
| BORLANDC | 0х0540 | Номер версии. |
| CDECL | 1 | Определен, если установлено соглашение о вызове cdecl; в противном случае не определен. |
| CHARUNSIGNED | 1 | Определен по умолчанию (показывает, что char по умолчанию есть unsigned char). Можно аннулировать ключом -К. |
| CONSOLE | Определен при компиляции консольных приложений. | |
| CPPUNWIND | 1 | Разрешение разматывания стека; определен по умолчанию. Для аннулирования можно применить ключ -xd-. |
| cplusplus | 1 | Определен при компиляции в режиме C++. |
| DLL | 1 | Определен, если компилируется динамическая библиотека. |
| FLAT | 1 | Определен при компиляции в 32-битной модели памяти. |
| MIХ86 | Определен всегда. Значение по умолчанию — 300. (Можно изменить значение на 400 или 500, применив соответственно ключи /4 или /5 в командной строке.) | |
| MSDOS | 1 | Целая константа. |
| MT | 1 | Определен, если установлена опция -WM. Она означает, что будет присоединяться мультили-нейная (multithread) библиотека. |
| PASCAL | 1 | Определен, если установлено соглашение о вызове Pascal. |
| TCPLUSPLUS | 0х0540 | Определен, если компиляция производится в режиме C++ (аналогично bcplusplus ). |
| TEMPLATES | 1 | Определен для файлов C++ (показывает, что поддерживаются шаблоны). |
| TLS | 1 | Thread Local Storage. В C++Builder определен всегда. |
| TURBOC | 0х0540 | Номер версии (аналогичен BORLANDC ). |
| WCHAR T | 1 | Определен только в программах C++ (показывает, что wear t — внутренне определенный тип. |
| WCAR T DEFINED | 1 | То же, что и WCHAR Т. |
| Windows | Определен для кода, используемого только в Windows. | |
| WIN32 | 1 | Определен для консольных и GUI-приложений. |
Как видите, многие предопределенные макросы C++Builder отражают те или иные установки параметров компиляции, задаваемые в командной строке (при ручном запуске компилятора Ьсс32.ехе). Те же самые установки могут быть выполнены и в интегрированной среде через диалог Project Options, который мы еще будем рассматривать в этой главе.
Макросы с параметрами
Макросы могут выполнять не только простую текстовую подстановку. Возможно определение макросов с параметрами, напоминающих функции языка С, например:
#define PI 3.14159265
#define SQR(x) ( (x) * (x) )
#define AREA(x) (PI * SQR(x))
#define MAX(a, b) (<a)>(b) ? (a): (b))
…
circleArea = AREAfrl + r2);
cMax = MAX(i++, j++);
Третье макроопределение показывает, что макросы могут быть вложенными. После каждого расширения макроса препроцессор снова сканирует полученный текст на предмет того, не содержит ли он идентификаторов, в свою очередь являющихся макросами. Исключением являются случаи, когда расширение содержит собственное имя макроса или является препроцессорной директивой.
Обратите внимание на скобки в показанных 'выше определениях. Можно сформулировать такое правило: каждый параметр и все определение в целом должны заключаться в скобки. Иначе при вхождении макроса в выражение могут появляться ошибки, связанные с различным приоритетом операций. Рассмотрите такой случай:
#define SQR(x) х*х binom = -SQR(a + b) ;
При расширении макроса получится:
binom = -a + b*a + b;
Порядок оценки выражения окажется совсем не тем, что подразумевался.
Преобразование в строку
В макросах может применяться специальная операция преобразования в строку (#). Если в расширении макроса параметру предшествует эта опе-
рация, то выражение-аргумент будет преобразовано в литеральную строку, заключенную в двойные кавычки. Вот один пример:
#define SHOWINT(var)
printf(#var " = %d\n", (int)(var))
int iVariable = 100;
SHOWINT(iVariable) ;
Последняя строчка расширяется в
printf("iVariable"" = %d\n", (int)(iVariable));
и печатает
iVariable = 100
В С примыкающие друг к другу литеральные строки при компиляции соединяются в одну строку.
Конкатенация
Операция конкатенации (##) позволяет составить из нескольких лексем единое слово. Получившийся элемент повторно сканируется для обнаружения возможного идентификатора макроса. Рассмотрите такой код:
#define DEF_INT(n) int iVar ## n
…
DEF_INT(One); // Расширяется в int iVarOne;
DEF_INT(Two); // Расширяется в int iVarTwo; и т.д.
Особенности C++Builder
В этом разделе мы обсудим два вопроса: особенности реализации языка в C++Builder и управление компилятором в IDE (диалог Project Options).
Расширения языка С
C++Builder поддерживает использование ряда ключевых слов, отсутствующих в стандартных ANSI C/C++. В таблице 4.4 перечислены все такие ключевые слова, которые могут применяться в программах на С. Многие из них могут записываться с одним или двумя начальными символами подчеркивания либо без них. Это сделано для того, чтобы можно было переопределить в препроцессоре какое-либо ключевое слово (например, форму без подчеркивания), сохранив возможность использования исходного слова (в форме с подчеркиванием). Рекомендую вам всегда пользоваться формой с двумя подчеркиваниями.
Таблица 4.4. Расширения набора ключевых слов языка С
| Ключевые слова |
Описание |
||
| asm
_asm __asm | Позволяет вводить код ассемблера непосредственно в текст программы на C/C++. Синтаксис:
__asm операция операнды ;_ или перевод_ строки Можно сгруппировать сразу несколько инструкций ассемблера в одном блоке asm: __asm { группа_ инструкций } | ||
| cdecl
_cdecl __cdecl | Специфицирует функцию как вызываемую в соответствии с соглашениями языка С. Перекрывает установки по умолчанию, сделанные в IDE или препроцессорных директивах. | ||
| _Except | Служит для управления исключениями в программах на С. | ||
| _Export
__export | Служит для экспорта из DLL классов, функций или данных. (См. главу 2, где приведен пример построения DLL.) | ||
| _fastcall
__fastcall | Специфицирует функцию как вызываемую в соответствии с соглашением fascall (передача параметров в регистрах). | ||
| _Finally | Служит для управления исключениями в программах на С. | ||
| _Import
__import | Импортирует классы, функции или данные, находящиеся в DLL. | ||
| _Inline | Применяется для объявления в программах на С расширяемых функций (inline). Соответствует ключевому слову inline, которое имеется только в C++. | ||
| _Pascal
__pascal ___pascal | Специфицирует функцию как вызываемую в соответствии с соглашениями языка Pascal. | ||
| _stdcall
__stdcall | Специфицирует функцию как вызываемую в соответствии со стандартными соглашениями о вызове. | ||
| _Thread | Позволяет определять глобальные переменные, имеющие тем не менее отдельные копии для каждой из параллельно выполняющихся линий кода (threads). | ||
| _Try | Служит для управления исключениями в программах на С. |
В следующих далее разделах мы дадим пояснения к некоторым из дополнительных ключевых слов.
Соглашения о вызове
Соглашение о вызове определяет способ передачи параметров от вызывающей функции в вызываемую. То или иное соглашение может быть установлено по умолчанию в диалоге Project Options либо определяться модификатором в объявлении конкретной функции, например:
void _stdcall SomeDLLFunc(void);
Рассмотрим по порядку различные протоколы вызова, поддерживаемые в C+4-Builder.
Соглашение _cdecl является стандартным для программ на C/C++. Оно характеризуется тем, что аргументы при вызове помещаются на стек в порядке справа налево, и за очистку стека отвечает вызывающий. Кроме того, для функций _cdecl компилятор генерирует внутренние имена, начинающиеся с подчеркивания и сохраняющие регистр букв. Таким образом, внутренним именем функции SomeCFunc •будет _SomeCFunc.
Соглашение _pascal соответствует протоколу вызова функций в языке Pascal. Параметры помещаются на стек в порядке слева направо, а за очистку стека отвечает вызываемый. Внутреннее имя образуется переводом всех символов в верхний регистр; например, функция SomePascalFunc получит имя SOMEPASCALFUNC. Этот протокол вызова может быть более эффективен, чем _cdecl, особенно если функция вызывается из многих различных мест программы. Однако вызываемые таким образом функции не могут иметь переменного списка аргументов, как функции С.
Соглашение stdcall принято в 32-битных версиях Windows в качестве стандартного. Оно является своего рода гибридом двух предыдущих. Параметры помещаются в стек справа налево, однако за очистку стека отвечает вызываемый. Внутреннее имя совпадает с объявленным.
Соглашение fastcall широко применяется в визуальном программировании C++Builder, т. е. в библиотеке VCL. Первые три параметра, если это возможно, передаются в регистрах ЕАХ, ЕСХ и EDX. Параметры с плавающей точкой или структуры передаются через стек. Внутреннее имя образуется присоединением символа @; например, внутренним именем функции SomeFastFunc будет @SomeFastFunc.
Несколько слов о стеке. На стеке сохраняется состояние процессора при прерываниях, распределяется память для автоматических (локальных) переменных, в нем сохраняется адрес возврата и передаются параметры процедур. Адресация стека (в 32-битных системах) производится посредством специальных адресных регистров процессора — указателя стека ESP и базы стека ЕВР. Адрес, на который указывает регистр ESP, называют вершиной стека. Основные операции при работе со стеком — это PUSH (втолкнуть) и POP (вытолкнуть). Операция PUSH уменьшает значение указателя стека и записывает последний по полученному адресу. Операция POP считывает значение со стека в свой
операнд и увеличивает указатель стека. (В 32-битном режиме адресации стек выравнивается по границе двойного слова, т. е. при операциях PUSH и POP значение ESP всегда изменяется на 4.) Таким образом, стек при заполнении расширяется сверху вниз, и вершина стека является на самом деле нижней его точкой, т. е. имеет наименьший адрес.
Посмотреть, что происходит на уровне машинного кода при различных типах вызовов, проще всего с помощью отладчика, о котором мы будем говорить в следующей главе. Можно также компилировать исходный модуль программы в код ассемблера, для чего придется запустить компилятор из командной строки с ключом -S:
bсс32.ехе -S myfile.c
Псевдопеременные
Псевдопеременные C++Builder служат представлением аппаратных регистров процессора и могут использоваться для непосредственной записи и считывания их содержимого. Регистровые псевдопеременные имеют такие имена:
_AL _AH _AX _ЕАХ
_BL _BH _ВХ _ЕВХ
_CL _CH _СХ __ЕСХ
_DL _DH _DX __EDX
_CS _DS _ES _SS
_SI _DI _ESI _EDI
_BP _SP _EBP _ESP
_FS _GS _FLAGS
Псевдопеременные могут применяться везде, где допускается использование целой переменной. Регистр флагов содержит информацию о состоянии процессора и результате последней инструкции.
Управление исключениями
Исключение — это краткое название для исключительной ситуации, или, если говорить попросту, состояния программы при возникновении ошибки.
Что считается ошибкой, определяет (по крайней мере, в некоторых случаях) сам программист. Например, он может считать, что ошибка пользователя при вводе данных должна обрабатываться как исключение. Но чаще все-таки исключения применяют для обработки действительно аварийных ситуаций.
В стандартном С нет средств для управления исключительными ситуациями, однако в C++Builder имеются три дополнительных ключевых слова (_try, _except и _finally), которые позволяют организовать в программе т. н. структурированное управление исключениями, которое отличается от стандартного механизма исключений, встроенного в C++.
Мы не будем сейчас подробно обсуждать механизмы обработки исключений, отложив это до тех времен, когда мы будем изучать специфические средства языка C++. Сейчас мы покажем только синтаксис _try/_except/_finally с краткими пояснениями.
Возможны две формы структурированной обработки исключений:
try
защищенный_блок_операторов except(выражение) блок_обработки исключения
либо
_try
защищенный_блок_опера торов
finally
блок_обработки_завершения
Защищенный блок содержит код, заключенный в фигурные скобки, который может возбудить исключение. При возбуждении исключения выполнение блока прерывается и управление передается обработчику, следующему за пробным блоком.. Блок обработки исключения исполняется только при возбужденном исключении и в зависимости от оценки выражения оператора _except. Это выражение должно принимать одно из трех значений:
EXCEPTION_EXECUTE_HANDLER EXCEPTION_CONTINUE_SEARCH EXCEPTION_CONTINUE_EXECUTION
Эти значения вызывают соответственно исполнение обработчика (блока __except), продолжение поиска обработчика (перевозбуждение исключения во внешнем блоке _try, если таковой имеется) или возобновление выполнения кода с той точки, где было возбуждено исключение.
Блок обработки завершения исполняется в любом случае, вне зависимости от того, возбуждено исключение или нет.
После исполнения обработчика (любого из двух видов) управление передается следующему по порядку оператору, если, конечно, обработчик не выполняет возврат из функции или завершение программы и сам не возбуждает исключений.
Исключения могут генерироваться системой, например, при ошибках процессора типа деления на ноль, недопустимых инструкциях и т. д., либо возбуждаться функцией RaiseException () , которая объявлена как
void RaiseException(DWORD ее, DWORD ef, DWORD na,
const DWORD *a) ;
где еc — код исключения,
ef — флаг исключения (EXCEPTION_CONTINUABLE либо EXCE.PTI-
ONONCONTINUABLE),
па — число аргументов,
а — указатель на первый элемент массива аргументов.
Страница Advanced Compiler
Эта страница (рис. 4.2) позволяет управлять деталями генерации объектного кода.

Рис. 4.2 Страница Advanced Compiler диалога Project Options
Группа радиокнопок Instruction set задает тип процессора целевой системы. Установки этой группы эквивалентны ключам командной строки -3, -4, -5 и -6.
Группа Data alignment управляет выравниванием данных в памяти. Выравнивание может отсутствовать (Byte), либо данные могут располагаться по адресам, кратным 2, 4 или 8 байтам. В структурах, если необходимо, вводятся байты заполнения. Установки группы эквивалентны ключам командной строки -an, где п — 1, 2, 4 или 8.
Группа Calling convention задает соглашение о вызове, применяемое по умолчанию. (Register обозначает соглашение _fastcall.) Эквивалентные ключи командной строки — -рс (или -р-), -р, -рг и -ps.
Группа Register variables управляет созданием регистровых переменных. None запрещает их использование. Automatic разрешает компилятору размещать переменные в регистрах там, где это целесообразно, и Register keyword разрешает размещать в регистрах только переменные, объявленные как register. Радиокнопки соответствуют ключам -г-, -г и -rd.
Раздел Output имеет два флажка: Autodepedency information и Generate
underscores. Первый из них определяет, будет ли включаться в объектный файл информация о зависимостях между исходными файлами (необходимо для работы команды Make). Второй флажок указывает, что имена функций _cdecl должны снабжаться начальным символом подчеркивания. Установленные флажки соответствуют ключам -Х- и -и.
Раздел Floating point управляет генерацией кода арифметики с плавающей точкой. None показывает, что ваш код не использует чисел с плавающей точкой. Fast исключает промежуточные преобразования типов при арифметических вычислениях, как явные, так и неявные;
при сброшенном флажке все преобразования выполняются в строгом соответствии с правилами ANSI С. Correct Pentium FDIV генерирует код, исключающий возможность ошибки из-за дефекта в ранних версиях процессора Pentium. Соответствующие ключи командной строки — -f-, -ff и -fp.
Группа радиокнопок Language compliance задает версию языка, с которой совместим компилируемый исходный код. Вы можете выбрать стандартный ANSI С, С с расширениями Borland, “классическую” версию Кернигана-Ричи и язык Unix V. При написании приложений Windows имеет смысл выбрать либо ANSI, либо Borland, если вы хотите использовать какие-либо ключевые слова из расширенного набора, описанного в этой главе. Флажкам соответствуют ключи -A (ANSI), -AT или -A- (Borland), -АК (К & R) и -AU (Unix V).
Раздел Source управляет некоторыми аспектами интерпретации исходного кода. Флажок Nested comments разрешает вложенные С-комментарии, т. е. конструкции вида /*.../*...*/...*/. MFC compatibility позволяет транслировать код библиотеки MFC, используемой компилятором Microsoft Visual С. Поле Identifier length задает максимальное число значимых символов в идентификаторах языка С (в C++ длина идентификаторов не ограничивается).
Страница Compiler
Эта страница диалога показана на рис. 4.1.
В нижней части страницы вы видите две кнопки: Full debug и Release. Первая из них выполняет все установки параметров, позволяющие в полной мере использовать возможности отладчика C++Builder; вторая запрещает генерацию какой-либо отладочной информации и оптимизирует код для получения максимальной скорости выполнения. При изучении языка вам лучше всего воспользоваться кнопкой Full debug и не задумываться больше об установках, влияющих на отладку и эффективность кода.
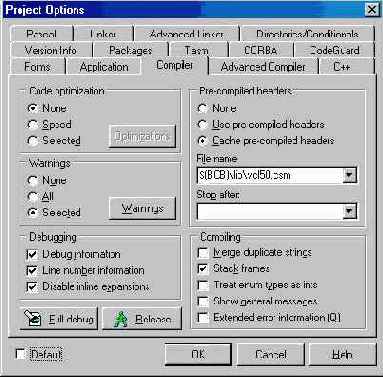
Рис. 4.1 Страница Compiler диалога Project Options
Коротко о разделах страницы Compiler.
Группа радиокнопок Code optimization позволяет полностью отключить оптимизацию, задать оптимизацию по скорости или выбрать отдельные опции оптимизации, включив радиокнопку Selected и нажав Optimizations. При этом откроется окно диалога со списком опций, в котором, кстати, показаны эквивалентные ключи командной строки, управляющие оптимизацией.
Группа Warnings управляет выдачей предупреждений. Включив соответствующую радиокнопку, можно запретить все, разрешить все предупреждения или управлять выдачей отдельных предупреждений. Диалог Compiler Warnings также показывает ключи командной строки. Я бы советовал вам разрешить выдачу всех предупреждений. Грамотно написанный код должен транслироваться не только без ошибок, но и без всяких замечаний со стороны компилятора.
Раздел Pre-compiled headers управляет прекомпиляцией заголовочных файлов.
Объем кода заголовочных файлов, включаемых в модуль исходный модуль, может достигать тысяч, если не десятков и сотен тысяч строк. К тому же часто эти заголовочные файлы включаются в каждый модуль проекта. Поскольку при разработке программы заголовочные файлы приходится изменять сравнительно редко (а стандартные заголовки вообще не меняются), имеет смысл компилировать все необходимые заголовки один раз и создать файл специального вида, который будет содержать всю необходимую “заголовочную” информацию в форме, обеспечивающей максимально быстрый доступ к ней. Компилятор C++Builder может генерировать такие файлы (с расширением .csm), •во много раз ускоряющие повторное построение проектов. Недостатком их можно считать разве что весьма большой размер — типичный файл прекомпилируемых заголовков может занимать от пяти до десяти мегабайт.
Кнопка None запрещает использование прекомпилируемых заголовков. Кнопка Use pre-compiled headers разрешает генерацию и использование файла компилированных символов (это другое название файлов .csm). Кнопка Cache pre-compiled headers заставляет компилятор кэшировать прекомпилируемые заголовки, т. е. хранить их информацию в памяти, а не загружать csm-файл заново, когда в этом возникает необходимость. Это полезно, когда вы транслируете сразу несколько файлов, но может и замедлять компиляцию, если память системы невелика. В поле редактирования File name задается имя файла компилированных символов. В поле Stop after можно ввести имя файла, после компиляции которого генерация прекомпилируемых заголовков прекращается. Это должен быть файл, включаемый в исходный модуль непосредственно, а не в другом заголовке (как, например, windows.h включает массу других заголовочных файлов). • Раздел Debugging управляет включением отладочной информации в объектные файлы, создаваемые компилятором (флажки Debug information и Line numbers). Кроме того, флажок Disable inline expansions позволяет запретить расширения inline-функций, т. е. непосредственную вставку кода функции на месте ее вызова. Это упрощает отладку.
Если вы хотите отлаживать программу, то должны убедиться, что флажок Create debug information на странице Linker также установлен.
Раздел Compiling управляет общими аспектами компиляции. При помеченном флажке Merge duplicate strings компилятор сопоставляет встречающиеся литеральные строки и, если две или более строк совпадают, генерирует только одну строку. Это делает программу несколько более компактной, но может приводить к ошибкам, если вы модифицируете одну из строк. При установке флажка Stack frames компилятор генерирует стандартные кадры стека функций, т. е. стандартный код входа и возврата. Этот флажок должен быть установлен, если вы хотите отлаживать 'функции модуля. Если флажок сброшен, то для функций, не имеющих параметров и локальных переменных, будет генерироваться нестандартный, сокращенный код. При установке Treat enum types as ints компилятор отводит под перечисления 4-байтовое слово. Если флажок сброшен, отводится минимальное целое (1 байт, если значения перечислимого типа лежат в диапазоне 0-255 или -128-127). Show general messages разрешает выдачу общих сообщений компилятора (не являющихся предупреждениями или сообщениями об ошибках). Флажок Extended error information разрешает выдачу расширенных сообщений об ошибках компилятора (вплоть до контекста синтаксического анализатора и т. п. — простому человеку ни к чему).
Страница Directories/Conditionals
На этой странице диалога Project Options (рис. 4.3) расположены несколько полей редактирования, позволяющих задавать стандартные каталоги по умолчанию — библиотек, заголовочных файлов и т. д. Нас на этой странице интересует сейчас только раздел Conditionals.
В поле Conditional defines можно определять символы C/C++, языка Object Pascal и компилятора ресурсов, которые будут, например, управлять директивами условной компиляции в исходных файлах. Для присвоения символам значений используется знак равенства. Можно ввести в это поле сразу несколько определений, отделяя их друг от друга точкой с запятой, например:
NDEBUG;ххх=1;yyy-YES
Для ввода определений можно также воспользоваться редактором строк, отрывающимся при нажатии кнопки с многоточием.

Рис. 4.3 Страница Directories/Conditronals
В командной строке символы определяются с помощью ключа -D:
bcc32 -DNDEBUG -Dxxx=l -Dyyy=YES ...
Мы немного рассказали о ключах командной строки компилятора не столько для того, чтобы вы умели запускать bcc32.ехе вручную, а чтобы дать вам некоторые г начальные сведения, которые помогут вам разбираться в Ьрг-файлах проектов C++Builder. Полное руководство по запуску компилятора из командной строки вы можете найти в оперативной справке в разделах command-line compiler и command-line options.
Заключение
Эта глава завершает предварительный курс по С, включая имеющиеся в C++Builder различные расширения языка. Прежде чем заняться вплотную объектно-ориентированным программированием на C++, мы считаем целесообразным познакомить вас с принципами отладки программ в IDE, чем мы и займемся в следующей главе.
Типичное применение препроцессорных директив
В этом коротком разделе мы покажем только некоторые из наиболее распространенных случаев, когда препроцессорные директивы могут оказаться полезны.
Предотвращение включения файлов
Иногда при использовании заголовков может происходить дублирование кода из-за повторного включения некоторого файла. (Допустим, у вас имеется исходный файл myprog.c, который подключает директивой # include два заголовка headerl.h и header2.h. Если, в свою очередь, оба этих файла подключают некоторый headerO.h, то последний будет дважды включен в исходный файл myprog.c. Это ни к чему, хотя обычно и не приводит к ошибке.)
Чтобы предотвратить повторное включение кода заголовочного файла, можно организовать контроль следующим образом (как говорят, “поставить часового”):
/*
** header0.h: Заголовочный файл, который может оказаться
** многократно включенным...
*/
#ifndef _HEADERO_H
#define _HEADERO_H
/* /
** Здесь идут макросы, определения типов
** и т.д. вашего заголовочного файла...
*/
*endif
Переключение разделов кода
Директивы условной компиляции могут использоваться для простого переключения между двумя различными вариантами кода — старым и экспериментальным алгоритмом, например. Это можно сделать так:
/*
** Измените определение на 0, чтобы вернуться к старому варианту.
*/
*define NEW_VER I
#if NEW_VER /*
** Экспериментальный код.
*/
#else /*
** Старый код.
*/
*endif
Или, если не вводить дополнительный идентификатор:
/*
** Измените на 1, когда новый код будет отлажен.
*/
*if 0 /*
** Экспериментальный код.
*/
#else /*
* * Старый код.
*/
*endif
Отладочные диагностические сообщения
При отладке программ можно с большой пользой применять макросы, генерирующие операторы вывода различных сообщений с указанием файла и номера строки, например:
#define INFO(msg)
printf(#msg "\n")
#define DIAG(msg)
printf("File " _FILE_ " Line %d: " \ #msg "\n", _LINE_)
void SomeFunc(void)
{
INFO(Entering SomeFunc.);
/* Выводит информационное сообщение. */
if (someError)
DIAG(Error encountered!);
/* Выводит сообщение об ошибке. */
INFO(Exiting SomeFunc...) ;
}
Макрос assert()
В заголовочном файле assert.h определен макрос assert (), выполняющий примерно то же самое, что и показанный выше пример. Его “прототип” можно записать как
void assert(int test);
Макрос расширяется в оператор if, проверяющий условие test. Если его значение равно 0, печатается сообщение Assertion failed: с указанием имени файла и номера строки. Вот пример:
#include <assert.h>
…
assert(!someError) ;
Если перед включением 41айла assert.h определить символ ndebug, операторы assert () будут “закомментированы”.
Управление компилятором
В этом разделе мы рассмотрим установки диалога Project Options, имеющие отношение к программам на С. В основном это будет касаться страниц Compiler и Advanced Compiler этого диалога. Он открывается выбором Project | Options в главном меню.
Условная компиляция
Можно производить выборочную компиляцию различных участков кода в зависимости от оценки некоторого константного выражения или определения идентификатора. Для этого служат директивы #if, #elif, #else и #endif. Общая форма применения директив условной компиляции следующая:
# выражение_1
группа_операторов 1
[# elif выражение_2
группа_опера торов_2
# elif выражение_3
группа_ операторов_ 3...]
[# else группа операторов else]
#endif
Первая группа операторов компилируется, если выражение_1 истинно; в противном случае операторы ее опускаются. Вторая группа компилируется, если выражение_1 ложно и выражение_2 истинно и т. д. Группа #else компилируется только в том случае, если все условные выражения ложны. Конструкция условной компиляции должна заканчиваться директивой #endif.
Разделы #elifH#else могут отсутствовать. Необходимыми элементами условной конструкции являются только директивы #if и #endif.
Операции в условиях #if
Выражения в директивах могут содержать обычные операции отношения <, >, <=, >= и ==. С их помощью можно проверять, например, значения предопределенных макросов или идентификаторов, определяемых директивой #define. В директивах препроцессора имеется также одна специальная операция defined. Она позволяет проверить, определен ли некоторый символ, например:
#define TEST
#if defined(TEST)
testFile = open("TEST.$$$", 0_CREAT | 0_TEXT) ;
#else testFile = -1;
#endif
Операция defined может комбинироваться с логическим отрицанием (!). ! defined (Sym) будет истинным, если Sym не определен.
Директивы #ifdef и ftifndef
Эти две директивы эквивалентны соответственно #if defined и #if !defined.
Другие инструменты отладки
В IDE имеются и другие инструменты отладки помимо описанных выше. Мы расскажем о них очень коротко, поскольку применять их приходится не слишком часто.
Диалог Evaluate/Modify
Этот диалог (рис. 5.14) служит для оценки выражений и изменения значений переменных. Его можно открыть командой Run | Evaluate/Modify или из контекстного меню редактора, установив курсор на нужной переменной или выделенном выражении.

Рис. 5.14 Диалог Evaluate/Modify
В поле Expression вводится выражение, которое требуется оценить. При нажатии кнопки Evaluate результат оценки отображается в поле Result. Если вы хотите изменить значение переменной, введите новое значение в поле New value и нажмите кнопку Modify.

Диалог Evaluate/Modify можно использовать в качестве простого калькулятора, позволяющего вычислять арифметические выражения и оценивать логические условия. В выражениях можно смешивать десятичные, восьмеричные и шестнадцатеричные значения. Результат вычисления выводится всегда в десятичном виде, поэтому очень просто, например, перевести шестнадцатеричное число в десятичное. Введите численное выражение в поле Expression и нажмите Evaluate. Поле Result покажет результат вычисления.
Окно CPU
Это окно, показанное на рис. 5.15, открывается командой View | Debug Windows | CPU главного или View CPU контекстного меню редактора.
Окно имеет пять отдельных панелей. Слева вверху находится панель дизассемблера. Она показывает строки исходного кода (если в контекстном меню панели помечен флажок Mixed) и генерированные для них машинные инструкции. В окне CPU можно устанавливать контрольные точки, как в редакторе, и выполнять отдельные инструкции командами Step Over
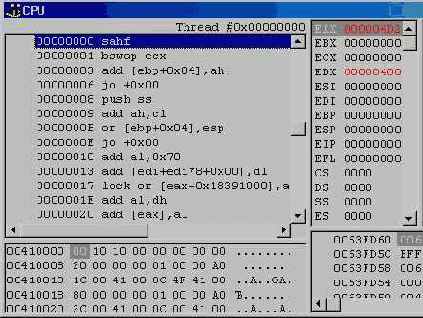
Рис. 5.15 Окно CPU
и Trace Into. На рисунке вы видите фрагмент программы, приведенной в начале главы — заголовок цикла for и начало блока ассемблерных инструкций.
Справа вверху находятся две панели, отображающие состояние регистров и флагов процессора. Содержимое регистров, модифицированных в результате последней инструкции, выделяется красным цветом.
Под панелью дизассемблера расположена панель дампа памяти. Панель справа внизу показывает “сырой” стек программы. Положение указателя стека соответствует зеленой стрелке. Каждая из панелей окна CPU имеет свое собственное контекстное меню, позволяющее выполнять все необходимые операции. Мы не будем здесь подробно разбирать отладку с помощью окна CPU, поскольку, чтобы им пользоваться, нужно хорошо знать язык ассемблера. Однако, если вы имеете о нем хотя бы смутное представление, вам будет интересно посмотреть на инструкции, которые генерирует компилятор. Разобраться в них не так уж и трудно, и иногда это помогает написать более эффективный исходный код.
У отладчика имеется также окно FPU, отображающее состояние процессора плавающей арифметики.
Стек вызовов
Окно стека вызовов (рис. 5.16) открывается командой View Debug Windows 1 Call Stack.
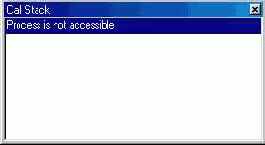
Рис. 5.16 Окно Call Stack
В окне показан список функций, вызванных к данному моменту и еще не завершившихся. Функция, вызванная последней, находится вверху списка. Для функций, имена которых неизвестны, указывается только адрес и имя модуля, как, например, для третьей сверху функции на рисунке. Если дважды щелкнуть на имени некоторой функции, в редакторе будет показан ее исходный код или, если он недоступен, будет открыто окно CPU на соответствующем адресе.
Исследование стека вызовов бывает полезно при возникновении ошибок типа нарушения доступа. На вершине стека будет находиться функция, получившая управление непосредственно перед ошибкой.
Команда Go to Address
Эта команда позволяет отыскать в исходном коде строку, соответствующую некоторому адресу, например, адресу инструкции, вызвавшей ошибку. Если выбрать Goto Address в меню Search или контекстном меню редактора кода (программа должна быть запущена), то появится диалоговая панель, в которой вводится нужный адрес. Отладчик попытается найти соответствующий ему исходный код, который в случае успешного поиска будет показан в редакторе. Если адрес находится за пределами вашего кода, будет выведено сообщение о том, что адрес не может быть найден.
Команда Program Reset
Иногда отлаживаемая программа “зависает” так, что никаким образом нельзя довести ее до сколько-нибудь нормального завершения. В этом случае можно прибегнуть к команде Run | Program Reset, которая аварийно завершает программу приводит ее в исходное состояние. Нужно сказать, что это крайнее средство и не следует им пользоваться просто для того, чтобы побыстрее закончить сеанс отладки. Windows этого не любит, и после команды Program Reset с IDE и системой могут происходить странные вещи.
Отладка программ
В этой главе вы познакомитесь с основными приемами отладки кода с помощью встроенного отладчика IDE. Это мощный инструмент, обладающий широкими возможностями вплоть до отладки на уровне машинного кода.
Программисты часто пренебрегают имеющимися в их распоряжении отладчиками и не используют их в полной мере, полагаясь на собственную сообразительность и пользуясь кустарными приемами отладки. Не берите с них пример, тем более что работать со встроенным отладчиком C++Builder очень просто, как вы сами скоро убедитесь. Следует также подчеркнуть, что отладчик является еще и прекрасным инструментом изучения языка, который позволяет производить наглядные эксперименты с различными языковыми конструкциями.
Элементы отладки
Наиболее общими приемами отладки являются установка контрольных точек, наблюдение за переменными и пошаговое исполнение кода.
Контрольные точки
Программа, запущенная под управлением отладчика IDE, исполняется как обычно, т. е. с полной скоростью, пока не будет встречена контрольная точка (breakpoint). Тогда отладчик приостанавливает программу, и вы можете исследовать и изменять содержимое переменных, исполнять операторы в пошаговом режиме и т. д.
Контрольные точки в C++Builder 4 могут быть четырех видов: в исходном коде, на адресе, на данных и точки загрузки модуля.
Контрольные точки в исходном коде
Это самый распространенный вид контрольных точек. Точка представляет собой маркер, установленный на некоторой строке исходного кода. Когда управление достигает этой строки, программа приостанавливается.
Проще всего установить контрольную точку такого типа прямо в редакторе кода, щелкнув кнопкой мыши на пробельном поле редактора (слева от текста) рядом со строкой, на которой требуется приостановить программу. В пробельном поле появится красный маркер, и сама строка будет выделена красным цветом фона (рис. 5.2). Повторное нажатие кнопки мыши удаляет контрольную точку.

Рис. 5.2 Установка контрольных точек
Если теперь запустить программу кнопкой Run, она будет остановлена на контрольной точке (рис. 5.3).
Рис. 5.3 Остановка программы на контрольной точке
Зеленая пометка на маркере контрольной точки означает, что точка проверена и признана действительной. Могут быть и недействительные контрольные точки — такие, что установлены на строках, не генерирующих исполняемого кода. Это могут быть комментарии, объявления, пустые строки или операторы, исключенные при оптимизации программы.
Текущая точка исполнения показана в пробельном поле зеленой стрелкой. Она указывает строку, которая должна исполняться следующей. Программу можно продолжить кнопкой Run или выполнять ее операторы в пошаговом режиме, о чем будет сказано ниже.
То, что мы сейчас показали — это простые контрольные точки в исходном коде; контрольные точки могут быть также условными, со счетчиком проходов или комбинированного типа.
Если вы в данный момент экспериментируете с отладчиком, откройте окно списка контрольных точек (View Debug Windows Breakpoints). Оно отображает все имеющиеся контрольные точки. Контекстное меню окна позволяет запретить остановку программы на контрольной точки, не удаляя ее (пункт Enable). Кроме того, выбрав пункт Properties..., вы получите доступ к свойствам выбранной точки (рис. 5.4 и 5.5).
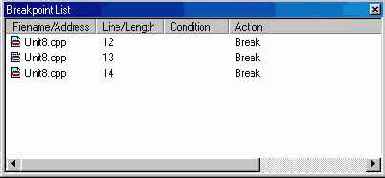
Рис. 5.4 Окно Breakpoint List

Рис. 5.5 Диалог Source Breakpoint
В поле Condition диалога Source Breakpoint Properties можно задать условие остановки на контрольной точке. Условие может быть любым допустимым выражением языка C/C++, которое можно оценить как истинное или ложное. Остановка по достижении контрольной точки будет происходить только в том случае, если условие истинно.
Контрольные точки со счетчиком проходов можно считать разновидностью условных. Требуемое число проходов вводится в поле Pass count. Если число проходов установлено равным п, остановка программы произойдет только на п-ом проходе через контрольную точку. Точки со счетчиком удобны при отладке циклов, когда вам нужно выполнить тело цикла определенное число раз и только потом перейти к пошаговому выполнению программы.
Счетчик может быть очень полезен, когда вам нужно определить, на каком проходе цикла возникает ошибка, вызывающая завершение программы. В окне списка контрольных точек отображается не только заданное, но и текущее число проходов точки (например, “7 of 16”). Задав число проходов, равное или большее максимальному числу итераций цикла, вы при завершении программы сразу увидите, сколько раз на самом деле он выполнялся.
Возможна комбинация этих двух типов контрольных точек, которую можно назвать точкой с условным счетчиком. Если для контрольной точки задано и условие, и число проходов, то остановка произойдет только на п-ом “истинном” проходе через нее. Проходы, для которых условие оказывается ложным, “не считаются”.
Условия и счетчик можно задавать для всех видов контрольных точек кроме точек загрузки модуля, т. е. для исходных, .адресных и точек данных.
Адресные контрольные точки
Адресные контрольные точки во всем аналогичны точкам в исходном коде за исключением того, что при их установке указывается не строка исходного кода, а машинный адрес инструкции, на которой нужно приостановить программу. Такие контрольные точки полезны, если ваша программа завершается аварийно. В этом случае Windows выводит панель сообщения, в которой указывается адрес инструкции, вызвавшей ошибку.
Адресные контрольные точки и их свойства устанавливаются в диалоге, вызываемом командой Run I Add Breakpoint | Address Breakpoint... главного меню или из контекстного меню окна Breakpoint List. Установить адресную точку можно только во время исполнения программы или при ее остановке (например, в другой контрольной точке). При дальнейшем выполнении программы отладчик приостановит ее на инструкции с указанным адресом. Если эта инструкция соответствует некоторой строке исходного кода, контрольная точка будет показана в окне редактора. В противном случае она будет отображена в панели дизассемблера окна CPU.
Контрольные точки данных
Контрольные точки на данных также устанавливаются при запущенной программе в диалоге, вызываемом командной Run | Add Breakpoint | Data Breakpoint... или Add Data Breakpoint в контекстном меню списка контрольных точек (рис. 5.6).

Рис. 5.6 Диалог Add Data Breakpoint
Контрольная точка на данных вызывает остановку программы, если в указанный элемент данных производится запись. В поле Address можно указать либо адрес, либо имя переменной. В поле Length указывается размер объекта, определяющий диапазон адресов, обращение к которым будет вызывать остановку. Для переменных встроенных типов размер устанавливается автоматически.
Как и для двух предыдущих в идов, для контрольных точек данных можно задать условие и счетчик.

Контрольные точки загрузки модуля
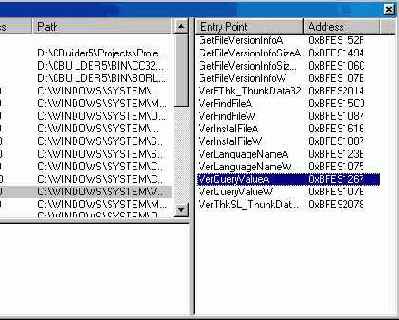
Команда Run Add Breakpoint | Module Load Breakpoint... открывает диалог Add Module, в котором задается имя файла (.exe, .dll, .осх или .bpl) для внесения его в список окна Modules. Загружаемые в память во время исполнения программы модули заносятся в это окно автоматически, однако если вы хотите, чтобы загрузка модуля вызывала остановку, то должны вручную ввести имя файла в список окна Modules до того, как модуль будет загружен (например, перед запуском программы).
На рис. 5.7 показано окно Modules. Добавить новый модуль в окно можно и через его контекстное меню.

(левая половина окна)
(правая половина окна)
Рис. 5.7 Окно Modules
Панель вверху слева показывает список модулей. Для выбранного модуля панель слева внизу показывает исходные файлы, входящие в его состав. Панель справа отображает список входных точек (глобальных символов) модуля.
Команда Run to Cursor
Если установить курсор редактора кода на некоторую строку исходного кода и запустить программу командой Run to Cursor главного или контекстного меню редактора (можно просто нажать F4), то курсор будет играть роль “временной контрольной точки”. Достигнув строки, где находится курсор, программа остановится, как если бы там находилась простая контрольная точка.
Команда Pause
Выполняющуюся в IDE программу можно приостановить, выбрав в главном меню Run | Program Pause или нажав кнопку Pause на инструментальной панели. Это более или менее эквивалентно остановке в контрольной точке. Если адресу, на котором остановилось выполнение, соответствует доступный исходный код, он будет показан в редакторе. В противном случае будет открыто окно CPU, отображающее машинные инструкции компилированной программы.
Наблюдение за переменными
Итак, вы остановили программу в контрольной точке. Обычно затем смотрят, каковы значения тех или иных переменных. Это называется наблюдением переменных (watching variables).
В IDE имеется специальное окно списка наблюдаемых переменных (рис. 5.8). Его можно открыть командой View | Debug Windows | Watches и ввести в него любое число переменных.
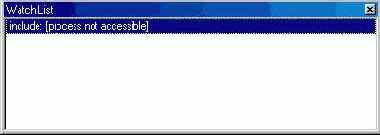
Рис. 5.8 Окно Watch List
Проще всего добавить переменную в список наблюдения можно, поместив курсор редактора кода на ее имя и выбрать в контекстном меню редактора Add Watch at Cursor. В окне наблюдений будет показано имя переменной и ее текущее значение либо сообщение, показывающее, что переменная в данный момент недоступна или наблюдение отключено (<disabled>). Можно ввести в список и целое выражение, если выделить его в редакторе и вызвать контекстное меню. Альтернативным методом добавления переменных или выражений является выбор в контекстном меню окна наблюдений пункта Add Watch... (пункт Edit Watch... служит для редактирования свойств уже имеющегося в списке наблюдения). Будет открыт диалог Watch Properties (рис. 5.9).

Рис. 5.9 Диалог Watch Properties
Помимо выражения, которое будет наблюдаться, диалог позволяет задать формат представления его значения. Поле Repeat count определяет число отображаемых элементов, если наблюдаемый объект — массив.
Быстрый просмотр данных
Редактор кода имеет встроенный инструмент, позволяющий чрезвычайно быстро узнать текущее значение переменной или выражения. Он называется подсказкой оценки выражения. Достаточно на секунду задержать курсор мыши над именем переменной или выделенном выражением, и под курсором появится окошко инструментальной подсказки с именем переменной и ее текущим значением (рис. 5.10). Причем — в отличие от окна наблюдений — таким способом можно просматривать и переменные, находящиеся за пределами текущей области действия (поскольку здесь не может возникнуть неоднозначности с именами).

Рис. 5.10 Подсказка с оценкой элементов массива
Выдачей подсказок управляет диалог Tools | Editor Options..., страница Code Insight (рис. 5.11). Чтобы разрешить отображение подсказок с оценками, следует убедиться, что флажок Tooltip expression evaluation помечен. Ползунок Delay задает задержку появления подсказок.
Эта страница управляет и другими “подсказочными инструментами” редактора кода, о которых мы расскажем при случае.

Рис. 5.11 Страница Code Insight диалога Editor Properties
Инспектор отладки
Инспектор отладки — это самый универсальный инструмент IDE для просмотра и модификации значений объектов данных, прежде всего объектов, принадлежащих классам. В их число входят и визуальные компоненты C++Builder. Они, в сущности, тоже не более чем представители классов, а инспектор отладки в этом случае является “инспектором объектов времени выполнения”.
Открыть инспектор отладки можно либо командой Run | Inspect... главного меню, либо из контекстного меню редактора, установив курсор на имени нужного объекта. На рис. 5.12 показан инспектор отладки, отображающий состояние помещенной на форму метки.
Инспектор отладки может использоваться только после остановки программы в контрольной точке.
Инспектор отладки имеет три страницы: Data, Methods и Properties.
Страница Data показывает все элементы данных класса с их значениями; тип выбранного элемента отображается в строке состояния инспектора.
Страница Methods показывает методы (элементы-функции) класса. В некоторых случаях эта страница отсутствует, например, при инспекции переменных простых типов.
Страница Properties показывает свойства объекта. При инспекции переменных, не являющихся представителями класса, эта страница также отсутствует.
Свойства и методы — это понятия, относящиеся к визуальному программированию, которые будут подробно рассматриваться в части III книги.
В приведенной ниже таблице перечислены пункты контекстного меню инспектора отладки.

Рис. 5.12 Инспектор отладки
Таблица 5.4. Пункты контекстного меню инспектора отладки
| Пункт меню |
Описание |
| Range... | Позволяет указать диапазон элементов массива, которые будут показаны. |
| Change... | Позволяет присвоить новое значение элементу данных. Если элемент можно изменять, в поле его значения имеется кнопка с многоточием. Ее нажатие эквивалентно команде Change. |
| Show Inherited | Помечаемый пункт, влияющий на объем отображаемой инспектором информации. Если помечен, то инспектор показывает не только элементы, объявленные в классе, но и унаследованные от базовых классов. |
| Inspect | Открывает новое окно инспекции для выбранного элемента данных. Это полезно при исследовании деталей структур, классов и массивов. |
| Descend | То же, что и Inspect, но выбранный элемент отображается в том же самом окне; нового окна инспекции не создается. Чтобы вернуться к инспекции прежнего объекта, выберите его в выпадающем списке в верхней части окна. |
| Type Cast... | Позволяет указать новый тип данных для инспектируемого объекта. Полезен в случаях, когда вы исследуете, например, указатель типа void*. |
| New Expression... | Позволяет ввести новое выражение, задающее инспектируемый объект. |
Инспекция локальных переменных
Командой View | Debug Windows | Local Variables можно открыть окно локальных переменных (рис. 5.13).

Рис. 5.13 Окно Local Variables
Оно внешне похоже на окно Watch List, но работает автоматически, отображая все локальные переменные и параметры текущей функции. Кроме того, его контекстное меню имеет пункт Inspect, открывающий окно инспектора для выбранного элемента списка. Выпадающий список наверху позволяет выбрать контекст, для которого нужно отобразить локальные переменные. Список совпадает с содержимым окна Call Stack, которое описано ниже.
Отладочные пункты меню
При отладке вам понадобится обращаться в основном к трем меню; это каскадное меню View | Debug Windows, меню Run и контекстное меню редактора кода. Пункты этих меню для управления отладкой приведены ниже в таблицах 5.1 - 5.3.
Таблица 5.1. Пункты меню Viev | Debug Windows
| Пункт |
Клавиша |
Описание |
|||
| Breakpoints | Ctrl+Alt+B | Открывает окно списка контрольных точек, показывающее активные контрольные точки и их свойства. | |||
| Call Stack | Ctrl+Alt+S | Открывает окно стека вызовов. Стек показывает, какие и в каком порядке вызывались функции, прежде чем управление достигло текущей точки программы. | |||
| Watches | Ctrl+Alt+W | Открывает окно наблюдения за переменными. Окно отображает список наблюдаемых переменных с их текущими значениями. | |||
| Local Variables | Ctrl+Alt+L | Открывает окно локальных переменных. В нем отображаются значения всех локальных переменных текущей функции. | |||
| Threads | Ctrl+Alt+T | Окно активных процессов и линий потока управления (threads). | |||
| Modules | Ctrl+Alt+M | Окно загруженных модулей — исполняемых файлов, динамических библиотек и пакетов запущенного проекта. | |||
| Event Log | Ctrl+Alt+E | Отображает протокол событий, происходящих при запуске проекта; какие события будут регистрироваться, можно задать на странице Event Log диалога Debugger Options. | |||
| CPU | Ctrl+Alt+C | Открывает окно состояния процессора. Отображает, в частности, компилированный код программы и содержимое регистров. | |||
| FPU | Ctrl+Alt+F | Открывает окно состояния FPU, отражающее содержимое его регистров и флагов. |
Таблица 5.2. Пункты меню Run
| Пункт |
Клавиша |
Описание |
|||
| Run | F9 | Запускает программу, при необходимости производя перед этим её сборку (Make). | |||
| Attach to Process... | Прикрепляет отладчик к уже выполняющемуся в данный момент процессу. | ||||
| Parameters... | Позволяет ввести аргументы командной строки или указать приложение, которое является “хозяином” отлаживаемой DLL. | ||||
| Step Over | F8 | Исполняет текущую строку исходного кода и переходит к следующей строке. | |||
| Trace Into | F7 | Исполняет текущую строку исходного кода; если строка содержит вызов функции, переходит к трассировке последней. | |||
| Trace to Next Source Line | Shift+F7 | Исполняет программу до следующей строки исходного кода. Например, если программа вызывает функцию API, требующую возвратно-вызываемой процедуры, отладчик остановит выполнение на входе в эту процедуру. | |||
| Run to Cursor | F4 | Исполняет программу до строки исходного кода, в которой установлен курсор редактора. | |||
| Run Until Return | Shift+F8 | Исполняет программу до возврата из текущей функции | |||
| Show Execution Point | Устанавливает курсор редактора кода на строку, в которой приостановлена программа. | ||||
| Program Pause | Приостанавливает выполнение программы, как только управление попадает в наличный исходный код. | ||||
| Program Reset | Ctrl+F2 | Закрывает программу. | |||
| Inspect... | Открывает диалог Inspect, в котором можно ввести имя инспектируемого объекта. | ||||
| Evaluate/Modify... | Ctrl+F7 | Открывает диалог Evaluate/Modify | |||
| Add Watch... | Ctrl+F5 | Открывает диалог Watch Properties | |||
| Add Breakpoint | Каскадное меню, позволяющее устанавливать контрольные точки различного вида (в исходном коде, на адресе, на данных, точки загрузки модуля). |
Для любой из вышеперечисленных команд' меню можно поместить на инструментальную панель соответствующую кнопку. (Откройте правой кнопкой мыши контекстное меню инструментальной панели и выберите Customize...; на странице Commands открывшегося диалога выберите нужную кнопку и. перетащите ее на инструментальную панель. Чтобы убрать с панели какую-нибудь кнопку, просто вытащите ее мышью за пределы главного окна C++Builder.) По умолчанию на панели инструментов размещены кнопки Run, Pause, Trace Into и Step Over.
Следующая таблица показывает пункты контекстного меню редактора в режиме приостановленной программы. В основном они дублируют перечисленные пункты главного меню, но в ряде случаев более удобны.
Таблица 5.3. Отладочные пункты контекстного меню редактора
| Пункт |
Клавиша |
Описание |
| Toggle Breakpoint | F5 | Переключает (устанавливает или сбрасывает) контрольную точку в строке, где находится курсор редактора. |
| Run to Cursor | F4 | То же, что и в меню Run. |
| Goto Address... | Позволяет указать адрес области памяти, которая будет отображаться в панели дизассемблера окна CPU. | |
| Inspect... | Alt+F5 | Открывает окно инспекции объекта, на имени которого находится курсор. |
| Evaluate/Modify... | То же, что и в меню Run. | |
| Add Watch at Cursor | Ctrl+F5 | Вносит в список наблюдения переменную, на имени которой находится курсор. |
| View CPU | То же, что Viev меню.| Debug Windows| CPU в главном |
Пошаговое исполнение кода
Одной из важнейших и самых очевидных операций при отладке является пошаговое исполнение кода. Когда программа приостановлена в контрольной точке, вы можете наблюдать значения различных переменных. Но чтобы найти конкретный оператор, ответственный за неправильную работу программы, нужно видеть, как эти значения меняются при исполнении отдельных операторов. Таким образом, выполняя операторы программы по одному, можно определить момент, когда значения каких-то переменных оказываются совсем не теми, что ожидались. После этого уже можно подумать, почему это происходит и как нужно изменить исходный код, чтобы устранить обнаруженную ошибку.
Эти команды могут выполняться из главного меню Run или с помощью кнопок инструментальной панели.
Step Over
Команда Step Over выполняет оператор, на котором приостановлено выполнение, и останавливается на следующем по порядку операторе. Текущий оператор выделяется в редакторе кода синим фоном и помечается зеленой стрелкой в пробельном поле. Если текущий оператор содержит вызов функции, она выполняется без остановок, и текущим становится первый оператор, следующий за возвратом из функции. Step Over “перешагивает” через вызов функции.
Trace Into
Команда Trace Into эквивалентна Step Over в случае, когда текущий оператор не содержит вызовов функций. Если же оператор вызывает некоторую функцию, то отладчик по команде Trace Into переходит на строку ее заголовка (заголовок при желании тоже можно рассматривать как исполняемый оператор, ответственный за инициализацию локальных переменных-параметров). При следующей команде (все равно — Step Over или Trace Into) текущим станет первый исполняемый оператор тела функции. Trace Into “входит внутрь” функции.
При выполнении команд Step Over и Trace Into в окне CPU отладчик исполняет не операторы, а отдельные машинные инструкции.
Заключение
Как видите, мы уделили отладчику IDE довольно много внимания. Но одно изучение, так сказать, “теории” отладки не научит вас отыскивать причины ошибок в неправильно работающей программе. Даже при наличии такого мощного инструмента, как отладчик C++Builder, отладка все равно остается чем-то вроде искусства. А любое искусство требует, во-первых, овладения техникой, т. е. знания имеющихся в вашем распоряжении средств, а во-вторых, опыта, приобретаемой в результате практической работы с отладчиком. Поэтому я советую вам не жалеть времени на изучение отладчика и побольше экспериментировать.
Предварительные шаги
Прежде всего, для исследования отладчика нам понадобится программа. В листинге 5.1 показана тестовая программа, вызывающая функции DoSomeMath () и DoSort () . Первая из них довольно бессмысленна и включена в программу только для того, чтобы продемонстрировать плавающую арифметику и соглашение _pascal. Вторая представляет собой вариант пузырьковой сортировки, частично реализованный на языке ассемблера.
При создании нового модуля debugC.C автоматически создается заготовка включаемого файла debugC.h, причем C++Builder сразу вводит в него директивы защиты от повторных включений, о которых мы говорили в прошлой главе. Кстати, главный исходный файл консольного проекта называется в 5-й версии Debug, bpf, а не Debug.срр
Листинг 5.1. Тексты программы Debug
/**********************************************************
* * Debug.срр: Главный файл проекта.
*/
#pragma hdrstop
#include <condefs.h>
USEUNIT("debugC.с") ;
#define main
/**********************************************************
* * debugC.h: Заголовок для модуля debugC.с.
*/
#ifndef debugCH
#define debugCH
double _pascal DoSomeMath(double r, double h);
void DoSort(int array[], int n) ;
*endif
/*******************************************
* * debugC.с: Программа для демонстрации отладчика.
*/
#pragma inline
#pragma hdrstop
#include <stdio.h>
#include "debugC.h"
const double Pi = 3.14159265;
#pragma argsused
int main(int argc, char *argv[])
{
double rad, vol;
int i, n = 8;
int iArr[8] = {-1, 23, 7, -16, 0, 11, 24, 3};
rad = 2.0;
vol = DoSomeMath(rad, 3.0);
printf("Volume = %10.6f\n", vol);
DoSort(iArr, n) ;
printf("Sorted array:");
for (i=0; i<n; i++)
printf("%6d", iArr[i]);
printf("\n") ;
return 0;
} /* main */
/************************************************
** Просто чтобы продемонстрировать вызов pascal.
*/
double _pascal DoSomeMath(double r, double h)
{
double s;
s = Pi * r*r;
return s * h;
} /* DoSomeMath */
** Сортировка с inline-ассемблером.
*/
void DoSort(int array[], int n)
{
int i, j;
for (i = n-1; i > 0; i-)
for (j = 0; j < i; j++)
_asm {
push esi
mov ecx, j
mov eax, array
mov edx, [eax+ecx*4]
mov esi, [eax+ecx*4+0x04]
cmp edx, esi
jle skip
mov [eax+ecx*4], esi
mov [еах+есх*4+0хб4], edx
skip:
pop esi }
} /* DoSort */
Прежде чем компилировать программу, нужно убедиться, что сделаны все необходимые установки проекта (диалог Project Options) и отладчика (диалог, вызываемый выбором Tools | Debugger Options... в главном меню).
Открыв уже известный вам диалог Project Options на странице Compiler, нажмите кнопку Full debug. Будут установлены все параметры компилятора и компоновщика, необходимые для отладки.
Диалог Debugger Options, показанный на рис. 5.1, имеет четыре страницы, из которых нам пока понадобится только одна — General. Рекомендую вам пометить на этой странице флажки Inspectors stay on top и Rearrange editor local menu on run — просто для удобства. При установленном втором флажке, например, контекстное меню редактора при запуске программы преобразуется таким образом, чтобы упростить доступ к пунктам управления отладкой.
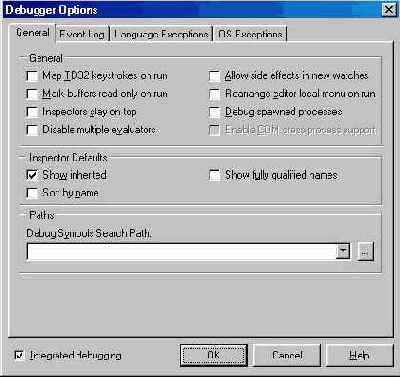
Рис. 5.1 Страница General диалога Debugger Options
Если вы хотите во время отладки иметь доступ к исходным текстам библиотеки VCL, то нужно установить флажок Use debug libraries на странице Linker диалога Project Options. Правда, компоновка отладочных библиотек может значительно замедлить компиляцию, поэтому не стоит прибегать к этому средству без необходимости.
Теперь я предлагаю вам посмотреть на различные меню, имеющие отношение к отладке.
Анонимные объединения
C++ допускает объявление объединений специального вида, называемых анонимными. Они не имеют этикеток и не являются именованными объектами. Последнее означает, что при обращении к разделам такого объединения не нужна операция-точка.
Глобальные анонимные объединения должны объявляться как static.
Аргументы по умолчанию
В прототипе функции язык C++ позволяет задать значения по умолчанию для некоторых параметров. Тогда при вызове функции соответствующие аргументы можно будет опустить, и компилятор подставит на их место указанные в прототипе значения. Правда, здесь существуют определенные ограничения.
Если вы задаете для какого-то параметра значение по умолчанию, то должны предусмотреть значения по умолчанию для всех последующих параметров функции. Таким образом, параметры со значениями по умолчанию должны стоять после всех остальных параметров в списке. Соответственно, если вы опускаете в вызове функции некоторый аргумент, то нужно опустить и все последующие аргументы. Короче говоря, в списке аргументов не должно быть пропусков.
Вот небольшая иллюстрация:
//////////////////////////////////////////////////
// Defaults.срр: Аргументы по умолчанию.
//
#include <stdio.h>
int Sum(int a, int b, int с = 0, int d = 0);
//Корректный прототип.
//
// Следующий прототип был бы некорректным:
// int Sum(int а, int b = 0, int с, int d = 0) ;
// int Sum(int a, int b, int с, int d)
// Определение функции.
{
return а + b + с + d;
}
int main(void) (
printf("l + 2 + 3 + 4 = %d\n", Sum(l, 2, 3, 4));
printf("1 + 2 + 3 = %d\n", Sum(l, 2, 3) ) ;
printf("1 + 2 = %d\n", Sum(1, 2));
//
// Недопустимый вызов:
// printf(" 1 + 2 + 4 = %d\n", Sum(l, 2,, 4)) ;
//
return 0;
}

В примерах программ этой главы мы не будем приводить строки, автоматически генерируемые при создании консольных приложении. Надеюсь, это не вызовет у вас никаких недоразумений.
Главная функция определяется в примерах как int main (void), но это не существенно, и если вы захотите посмотреть, как они работают, можно оставить заголовок, который генерирует C++Builder.
Функция Sum, как видите, вычисляет сумму четырех переданных ей чисел. Благодаря значениям по умолчанию последние два аргумента в вызове Sum можно не указывать, если требуется посчитать сумму всего двух или трех чисел.
Значения по умолчанию в прототипе не обязаны быть обязательно константами. Это могут быть, например, глобальные переменные или даже значения, возвращаемые функцией.
Часть II. Объектно-ориентированное программирование и язык C++
Модифицированный С
Объектно-ориентированное программирование
Классы C++
Потоки ввода-вывода
Шаблоны
Библиотека стандартных шаблонов
Управление исключениями
RTTI и приведение типов
В этой части мы будем изучать объектно-ориентированное программирование на C++. Конечно, C++ не единственный язык, работающий с классами и объектами. Есть Object Pascal, есть Java, есть и более старые языки вроде Smalltalk. Поэтому, наверное, имеет смысл поговорить и об общих принципах организации подобных языков.
Помимо общих принципов объектной архитектуры и классов языка C++ мы поговорим о таких вещах, как стандартные потоки, исключения, шаблоны и RTTI. К концу этой части книги вы узнаете практически все о стандартном ANSI C++, и в части III мы перейдем к изучению средств визуального программирования C++Builder.
Дополнительные обозначения операций
Для ряда операций, в основном логических, в ANSI C++ введены альтернативные обозначения (ключевые слова) в стиле языка Pascal. Это было сделано потому, что на некоторых национальных клавиатурах трудно вводить знаки вроде “^” или “~”. Ниже перечислены все такие обозначения.
| Ключевое слово | Эквивалентный знак | Операция | |||
| and | && | Логическое AND | |||
| and eq | &= | Присвоение поразрядного AND | |||
| bitand | & | Поразрядное AND | |||
| bitor | | | Поразрядное OR | |||
| coiripl | ~ | Поразрядное NOT (дополнение до 1) | |||
| not | ! | Логическое NOT | |||
| not eq | ! = | Отношение “не равно” | |||
| or | || | Логическое OR | |||
| or eq | |= | Присвоение поразрядного OR | |||
| xor | ^ | Поразрядное исключающее OR | |||
| xor eq | ^= | Присвоение исключающего OR |
К сожалению, в C++Builder, даже в 5-й версии, эти ключевые слова пока не реализованы, но мы все равно их здесь перечислили. О них следует знать, особенно если вам придется переносить в C++Builder код, написанный для других компиляторов, например, Borland C++ 5.
Модифицированный С
В некоторых своих аспектах язык C++ является, так сказать, улучшенным С. В этой главе мы не будем касаться совершенно новых возможностей C++, таких, как объектно-ориентированное программирование и шаблоны, а остановимся на тех моментах, которые можно рассматривать в качестве модификаций старого языка С.
Глобальные константы
В С глобальная константа, т. е. инициализированная глобальная переменная с модификатором const, имеет своей областью действия всю программу (доступна для внешней компоновки), как и любая переменная без const. Другими словами, ее имя заносится в список глобальных символов объектного модуля и поэтому к ней можно обращаться из любого другого исходного файла программы.
В C++ областью действия глобальных констант является текущий файл, аналогично глобальным переменным static. Для того, чтобы к глобальной константе можно было обращаться из других компилируемых модулей, она должна быть определена как extern const, например:
extern const double eConst = 2.718281828;
В модулях, которые будут обращаться к такой константе, она, как и в С, должна быть объявлена внешней:
extern const double eConst;
Такое поведение глобальных констант C++ упрощает их объявление. Можно поместить определение константы (без extern) в заголовочный файл и включать его во все исходные модули, где она используется. Тем самым будет генерированы отдельные константы для каждого модуля, с одним именем и одинаковыми значениями. В С такие объявления вызывали бы ошибку дублирования определения.
Имена-этикетки
В языке C++ этикетки структур, объединений и перечислений являются именами типов в отличие от С, где новые имена типов могут порождаться только оператором typedef. Тем самым определение новых типов упрощается. Вместо старого определения
struct Person {
struct Person *link;
char firstName[32];
char lastName[32];
};
struct Person aPerson;
или введения нового имени с помощью typedef достаточно будет написать
struct Person {
Person *link;
char firstName[32];
char lastName[32] ;
};
Person aPerson;
Person, таким образом, будет настоящим именем типа.
Модификатор const
В языке С модификатор const означает, что значение переменной после инициализации не может быть изменено. В C++ переменные с const рассматриваются как истинные константные выражения. Поэтому в отличие от С в C++ допускается их использование в объявлении массивов:
const int aSize = 20 * sizeof(int);
char byteArray[aSize];
Объявления переменных
Локальные переменные в С должны объявляться в начале блока, т. е. до всех исполняемых операторов. В C++ переменные можно объявлять где угодно. Это предоставляет программисту определенные удобства и уменьшает возможность ошибок, позволяя размещать объявления переменных ближе к тому месту, где они используются. Вот один пример:
#include <stdio.h>
int main(void) {
int n = 10;
printf("Hello! i =") ;
int i;
for (i=0; i<n; i++)
{
printf("%4d", i);
}
printf("\nAfter loop i = %d\n", i);
return 0;
Счетчик i объявляется непосредственно перед заголовком цикла for, а не в начале блока.
Можно объявлять переменную счетчика прямо в заголовке цикла, как это часто и делается:
for (int i=0; i<n; i++) {...}
Ранее считалось, что при таком объявлении i остается доступной и после завершения цикла. Но стандарт ANSI постулирует, что область действия объявленной в заголовке цикла переменной ограничивается телом цикла. То же самое относится к циклам while.
Операции распределения памяти
В языке C++ для управления динамической памятью введены операции new и delete (для массивов new [ ] и delete [ ]). В С для этого применялись в C++, однако новые операции имеют некоторые преимущества.
Переопределение операций new и delete
Стандартные (глобальные) версии операций new и delete можно переопределить или перегрузить, чтобы придать им некоторые дополнительные свойства или обеспечить возможность передачи им дополнительных аргументов. Это бывает полезно при отладке, когда требуется проследить все выделения и освобождения динамической памяти:
#include <stdlib.h>
#include <stdio.h>
////////////////////////////////////////////////////
/ / Переопределение операций new и delete.
//
void* operator new(size_t size)
{
printf("%u bytes requested.\n", size);
return malloc(size);
void operator delete(void *ptr)
{
printf("Delete performed.\n") ;
free(ptr) ;
}
/////////////////////////////////////////////////////////////
// Перегрузка new для выдачи дополнительной информации.
//
void* operator new (size t size, char *file, int line)
printf("%u bytes requested in file %s line %d.\n", size, file, line) ;
return malloc(size);
}
int main(void) {
double *dptr = new double; // Вызывает новую new.
*dptr = 3.14159265;
delete dptr; // Вызывает новую delete.
// Вызов перегруженной new.
dptr = new(_FILE_, _LINE_) double;
*dptr = 1.0;
delete dptr;
return 0;
}
Здесь используется механизм определения функций-операций C++. В этом языке можно переопределить или перегрузить практически любое обозначение операции, чтобы, например, можно было применять стандартные знаки арифметических операций к объектам созданных пользователем типов. Об этом мы будем говорить в следующих главах.
Обратите внимание на синтаксис определения и вызова функций-операций new и delete. Операция new должна возвращать пустой указатель, а ее первым параметром всегда является число затребованных байтов. Компилятор автоматически вычисляет это число в соответствии с типом создаваемого объекта. Возвращаемый указатель приводится к этому типу.
Перегруженная версия new может быть, кстати, определена таким образом, что она не будет выделять никакой новой памяти, а будет использовать уже существующий объект. Адрес, где нужно разместить “новый” объект, должен быть одним из дополнительных параметров функции-операции. Эта форма new известна как синтаксис размещения (placement syntax).
Размещающая форма new полезна, если требуется вызвать конструктор класса для уже существующего объекта или организовать какую-то специальную схему управления памятью.
Операция delete имеет тип void, а ее параметр — void*.
Обработка ошибок
В C++ имеется библиотечная функция 5et_new_handler().Он будет вызываться при любой ошибке выделения памяти.
#include <stdlib.h>
#include <stdio.h>
#include <new.h>
void MyHandler(void)
{
prir-tf("No memory!\n");
exit(l) ;
}
int main(void) {
set_new_handler (MyHandler) ; //Установка обработчика.
return 0;
}
Обработчик ошибок new должен:
либо возвратить управление, освободив память;
либо вызвать abort () или exit ();
либо выбросить исключение bad_alloc или производного класса.
Заключение
Теперь вы знаете о ряде конструкций языка C++, которые можно рассматривать в качестве модификаций старого С, не вносящих ничего принципиально нового. Принципиально новое начнется со следующей главы, где мы перейдем к классам и объектно-ориентированному программированию.
Операция разрешения области действия
В языке С локальная переменная скрывает глобальную с тем же именем. Другими словами, если функция объявляет переменную, одноименную глобальной переменной, то, хотя мы и остаемся в области действия последней, она оказывается недоступна для функции. Чтобы разрешить конфликт имен, компилятор считает, что все ссылки на данное имя относятся к локальной переменой.
В C++ имеется операция разрешения области действия, позволяющая в такой ситуации обращаться к глобальной переменной, предваряя ее имя символами “ : : ”. Вот пример, поясняющий разрешение области действия:
#include <stdio.h> int aVar = 111; // Глобальная переменная.
int main(void)
{
int aVar == 222; // Локальная переменная.
printf("Local aVar is %d.\n", aVar);
printf("Global aVar is, %d.\n", ::aVar);
return 0;
}
Отличия C++ от ANSI С
Есть несколько случаев, когда написанный на С код оказывается не корректным, если его компилировать в режиме C++.
Перегруженные функции
В программировании то и дело случается писать функции для схожих действий, выполняемых над различными типами и наборами данных. Возьмите, например, функцию, которая должна возвращать квадрат своего аргумента. В C/C++ возведение в квадрат целого и числа с плавающей точкой — существенно разные операции. Вообще говоря, придется написать две функции — одну, принимающую целый аргумент и возвращающую целое, и вторую, принимающую тип double и возвращающую также double. В С функции должны иметь уникальные имена. Таким образом, перед программистом встает задача придумывать массу имен для различных функций, выполняющих аналогичные действия. Например, Square-Int() и SquareDbl() .
В C++ допускаются перегруженные имена функций (термин взят из лингвистики), когда функции с одним именем можно тем не менее идентифицировать по их списку параметров, контексту, так сказать, в котором имя употребляется.
Рассмотрите следующий пример с вышеупомянутыми квадратами. Мы предусмотрели еще “возведение в квадрат” строки, когда результатом функции должна быть строка, в которой любые символы, кроме пробелов, удваиваются.
#include <stdio.h>
int Square(int arg)
{
return arg*arg;
}
double Square(double arg)
{
return arg*arg;
char *Square(const char *arg, int n)
{
static char res[256];
int j = 0;
while (*arg && j < n) { if (*arg != ' ') res[j++] = *arg;
res[j++] = *arg++;
}
res[j] = 0;
return res;
}
int main(void)
{
int x = 11;
double у = 3.1416;
char msg[] = "Output from overloaded Function!";
printf("Output: %d, %f, %s\n", Square (x) , Square (y) , Square (msg, 32) ) ;
return 0 ;
}
}
Результат работы программы показан на рис. 6.1.
Довольно понятно, что компилятор, когда ему встречается вызов перегруженной функции, видит только список фактических параметров, но

Рис. 6.1 Пример с тремя перегруженными функциями
тип, ею возвращаемый, в вызове никак не подразумевается. Поэтому нельзя перегружать функции, отличающиеся только типом возвращаемого значения.
По аналогичным причинам нельзя перегрузить функции, параметры которых различаются только наличием модификаторов const или volatile, либо ссылкой. По виду вызова их отличить нельзя.
Как это делается
Ничего сложного в механизме перегруженных функций, конечно, нет. Перегруженные функции являются, по сути, совершенно различными функциями, идентифицируемыми не только своим именем (оно у них одно и то же), но и списком параметров. Компилятор выполняет т. н. декорирование имен. дополняя имя функции кодовой последовательностью символов, кодирующей тип ее параметров. Тем самым формируется уникальное внутреннее имя.
Вот несколько примеров того, как для различных прототипов производится декорирование имени функции:
void Func(void); // @Func$qv
void Func(int); // @Func$qi
void Func(int, int); // @Func$qii
void Func(*char); // 8Func$qpc
void Func(unsigned); // @Func$qui
void Func(const char*); // @Func$qpxc
Тип возвращаемого значения никак не отражается на декорировании имени.
Спецификация связи
Если функция, написанная на C++, должна вызываться из программы на С, Pascal или языке ассемблера (и наоборот, что часто бывает при использовании существующих динамических библиотек), то механизм декорирования имен C++ создает некоторые трудности. Они могут быть причиной сообщений об ошибках при компоновке вроде “Неопределенный символ ххх в модуле уyу”.
Чтобы обойти возникающие из-за декорирования проблемы, используется спецификация extern "С". Она применяется в двух случаях: во-первых, когда следует запретить декорирование имени определяемой вами функции, и во-вторых, когда вы хотите информировать компилятор, что вызываемая вами функция не соответствует спецификации связи C++.
Вот примеры:
// Функция, которую можно вызывать из С (прототип):
extern "С" void FuncForC(void);
// Прототип функции из некоторой библиотеки не на C++:
extern "С" void SomeExtFunc (int);
// Определение - extern "С" не требуется, если включен
// прототип:
void FuncForC(void)
{
printf("Hello!\n");
}
// Вызов внешней функции:
SomeExtFunc(count);
Следует отличать спецификацию связи от соглашений o вызове. Функция, например, может вызываться в соответствии с соглашением Pascal (что означает определенный порядок передачи параметров и имя в верхнем регистре), но иметь спецификацию связи C++, т. е. декорированное имя. Алгоритм здесь такой: сначала формируется (если не указано extern "С") декорированное имя, а затем оно подвергается модификации в соответствии с соглаЕсли вы вызываете функции библиотек, написанных на С или языке ассемблера и у вас есть необходимые заголовочные файлы на С, то соответствующие директивы включения можно поместить в блок extern "С", как показано ниже. В противном случае нужно было бы модифицировать эти файлы, добавив спецификации связи к прототипам функций.
extern "С" { #include "asmlib.h" #include "someclib.h" }
Пространства имен
Рано или поздно практически каждый программист сталкивается с проблемой конфликта идентификаторов, особенно если проект разрабатывают несколько программистов либо привлекаются библиотеки классов, поставляемые кем-то другим. Приходится искать какой-то способ избежать употребления глобальных имен, используемых имеющимися библиотеками, другими программистами группы и т. п.
Язык C++ решает эту проблему, позволяя разбить проект на сегменты с различными пространствами имен (namespaces). Заключив свои символы в отдельное пространство имен, вы, по существу, снабжаете имя всякого типа, переменной и т. д. некоторым скрытым префиксом. Например, если определить пространство имен
namespace MYSPACE { int х;
}
то переменная х будет существовать в пространстве имен MYSPACE. Любые другие переменные х, принадлежащие глобальной области действия или другому пространству имен, не будут с ней конфликтовать. Чтобы явно обратиться к переменной, применяется операция разрешения области действия:
MYSPACE::х = 11;
Пространства имен могут быть вложенными:
namespace OUTER { int x;
namespace INNER { int x;
}
Соответственно, чтобы ссылаться на эти переменные, нужно будет написать:
OUTER::х = 11;
OUTER::INNER::x = 22;
Пространства имен можно создавать и не только в глобальной области действия, но и, например, в функциях. Но это редко имеет практический смысл.
Создание пространства имен
К созданию именных пространств можно отнести три момента:
Первоначальное объявление пространства.
Расширение пространства имен.
Определение анонимного пространства.
Первоначальное объявление пространства имен — это определение пространства с именем, еще не встречавшимся в программе. Синтаксис его следующий:
namespace новое_имя {тело пространства имен}
Тем самым в программе объявляется пространство имен с именем новое_имя.
Объявленное пространство имен можно расширять, в том же исходном файле или любом другом, применяя ту же конструкцию, но с уже имеющимся именем:
namespace существующее_имя [тело_пространства__имен]
Тела всех пространств с одинаковыми именами, определенных на глобальном уровне, составляют одно именное пространство. Каждый идентификатор в его пределах должен быть уникален.
Синтаксис C++ позволяет определять анонимные пространства имен:
namespase{
int x;
double у;
}
Все анонимные пространства имен в глобальной области действия данного файла составляют единое целое. Говоря проще, объявление глобальных символов как относящихся к анонимному пространству имен эквивалентно их объявлению с модификатором static:
static int x;
static double у;
Доступ к пространству имен
Доступ к элементам конкретного пространства имен может осуществляться тремя способами:
Путем явной квалификации имени.
Посредством квалифицирующего объявления.
С помощью директивы using.
Примеры явной квалификации имен мы уже приводили чуть выше. Имя снабжается префиксом, состоящим из идентификатора (квалификатора) пространства имен со знаком операции разрешения области действия.
Квалифицирующее объявление выглядит следующим образом:
using иденгификатор_пространства_имен::имя;
Элемент указанного пространства имен, идентифицируемый именем, объявляется как принадлежащий локальной области действия. После этого все не квалифицированные ссылки на имя будут рассматриваться как относящиеся к данному элементу. Вот пример:
namespace ALPHA {
int RetJ(int j) {return j;} } namespace BETA {
int RetJ(int j) {return (j * 2);}
}
int main(void) {
using BETA::RetJ; // Квалифицирующее объявление RetJ().
int x = 11;
printf("Calling RetJ(): %d\n"/ RetJ(x));
// Вызывает BETA::RetJ(). return 0;
}
Последняя форма доступа к пространству имен — директива using. Она имеет вид:
using namespace идентификатор пространства_имен;
В результате указанное пространство имен будет приниматься по умолчанию, если ссылка на некоторое имя не может быть разрешена локально (как и в общем случае, локальное объявление скрывает любое объявление в “более внешней” области действия). Вот пример, демонстрирующий различные моменты применения именных пространств:
#include <stdio.h>
namespace ALPHA {
int x = 11;
int у = 111;
int v = 1111;
} namespace BETA {
int x = 22;
int у - 222;
int z = 2222;
}
int main(void) {
using namespace ALPHA; // Конфликта не возникает до
using namespace BETA; // момента действительного
// обращения к элементам х и у.
using ВЕТА::х;
// Локальная квалификация х.
int z = 3333; // Локальная переменная.
printf ("Global х = %d, у = %d, z = %d, v = %d.\n", х, ALPHA::y, ::z, v);
// х квалифицирована
// локально, у - явно.
printf("Local z = %d.\n", z) ;
return 0;
}
Программа печатает:
Global х = 22, у = 111, z = 2222, v = 1111. Local z = 3333.
Здесь показан случай, когда могут возникать конфликты между двумя пространствами имен, используемыми одновременно. В теле главной процедуры указаны два именных пространства ALPHA и BETA, которые оба объявляют глобальные переменные х и у. В данный момент у компилятора не возникает никаких возражений. Ошибка случилась бы, например, если ниже мы обратились к переменной у без какой-либо квалификации. В общем, разберите внимательно этот пример — каким образом компилятор разрешает неоднозначные ссылки на различные символы.
Псевдонимы именных пространств
Можно объявлять псевдонимы для именных пространств, если, например, полная квалификация символа оказывается слишком уж длинной:
namespace BORLAND_INTERNATIONAL
{
// Тело именного пространства...
namespace NESTED_BORLAND_INTERNATIONAL
{
// Тело вложенного именного пространства... }
// Псевдонимы:
namespace BI = BORLAND_INTERNATIONAL;
namespace NBI = BORLAND_INTERNATIONAL::
NESTED_BORLAND_INTERNATIONAL;
Расширяемые функции
Определение функции транслируется компилятором в отдельный и относительно автономный блок объектного кода. При вызове функции в вызывающей процедуре (программе) генерируется инструкция CALL с предшествующим ей кодом, ответственным за передачу параметров, и последующим кодом очистки стека. Инструкция CALL передает управление коду функции, являющемуся внешним по отношению к вызывающей процедуре. Все это вы можете увидеть воочию в окне CPU отладчика.
По своем завершении функция возвращает управление инструкцией RET. Выполнение вызывающей процедуры возобновляется с инструкции, следующей за call.
Однако, если определить функцию с модификатором inline, компилятор, по крайней мере в принципе, генерирует встроенное расширение функции на месте вызова. Это напоминает расширение макроса. Тем самым из кода исключаются инструкции вызова, возврата, передачи параметров и т. д., что, естественно, уменьшает общее время выполнения. Но следует иметь в виду, что код функции будет воспроизводиться в исполняемом файле столько раз, сколько имеется операторов вызова в исходной программе. Если функция велика и вызывается из многих мест, объем исполняемого файла может заметно возрасти.
Вот простейший пример расширяемой функции:
#include <stdio.h>
inline int. Max(int a, int b)
{
return a > b? a : b;
}
int main(void)
int x = 11, у = 22;
printf("Max(%d, %d) = %d.\n", x, у, Мах(х, у)) ;
return 0;
}
Если зы хотите, чтобы компилятор генерировал расширения iniine-функций, нужно сбросить флажок Disable inline expansions на странице Compiler диалога Project Options.
Тут же следует сделать целый ряд оговорок относительно того, будет ли компилятор действительно генерировать встроенный код для функций, которые вы определили как inline.
Прежде всего, в самом стандарте ANSI сказано, что модификатор inline является лишь рекомендацией компилятору генерировать встроенное расширение функции. Наподобие модификатора register, который рекомендует разместить переменную в регистре процессора. Это не всегда возможно, поэтому компилятор может безо всяких предупреждений игнорировать модификатор inline.
Привлекая самые общие соображения, можно сформулировать следующее правило: для того, чтобы вызов iniine-функций замещался ее расширением, компилятор должен видеть определение функции в точке ее вызова. Если он ее не видит, то рассматривает функцию как внешнюю, т. е. определенную ниже или вообще в другом файле. Современные компиляторы по большей части однопроходные. Термин не имеет отношения к животному миру Австралии, а означает, что компилятор сканирует текст транслируемого модуля единственный раз и не может “заглянуть вперед”.
Компилятор Borland C++ не может расширять встроенные функции также в следующих случаях:
Если функция содержит операторы цикла или оператор выбора switch.
Если функция имеет тип не void и не содержит при этом оператора return.
Если она содержит встроенный код ассемблера.
В качестве иллюстрации рассмотрите такой пример:
/////////////////////////////////////////////////
// Inline.срр: Расширение inline-функций.
//
#pragma hdrstop
#include <condefs.h>
#include <stdio.h>
inline int Max(int, int);
int МахЗ(int, int, int);
int main(void) {
int x = 11, у = 22, z = 33, v = 44;
x = МахЗ(х, z, v) ;
z = Мах(х, у);
// Не расширяется - генерируется вызов!
printf("Max(%d, %d) = %d.\n", х, у, z);
return 0;
}
inline int Max(int a, int b) {
return a > b? a : b;
}
int МахЗ (int a, int b, int c)
{
b = Max(a, b);
// Эти вызовы расширяются как встроенные.
return Max(с, b) ;
}
Здесь функция Мах () определяется после main (), поэтому ее вызов из main () не расширяется как встроенный. Однако после определения Мах () дальнейшие ее вызовы (в Мах3 ()) уже расширяются. Воспользуйтесь отладчиком, чтобы это проверить — внутрь встроенной функции нельзя войти командой Trace Into; ее можно отлаживать только в окне CPU.
Лучше всего размещать определения расширяемых функций в заголовочных файлах (для обычной, определенной где-то вовне функции файл включал бы ее прототип).
Символьные константы
Типом символьной константы (символ, заключенный в апострофы) в С является int, В языке C++ символьная константа имеет тип char. Конечно, это различие практически несущественно, но можно придумать случай, когда из-за него код С окажется несовместимым с C++.
Символьные типы
В языке С тип char эквивалентен либо signed char, либо unsigned char; какому именно, определяется реализацией или установками компилятора. Обычно считается, что char — это signed char. В C++ char.
Различие трех символьных типов становится ясным в свете перегрузки функций/ о которой будет говориться в следующем разделе этой главы. Можно определить, например, такие перегруженные функции:
void OutC(char с)
{
printf("Unspec: %c\n", c);
}
void OutC(signed char c)
{
printf("Signed: %c\n",'c);
}
void OutC(unsigned char c)
{
printf("Unsigned: %c\n", c);
}
Для сравнения отметим, что перегрузить подобным образом функции для типа int невозможно:
void OutI(int i)
{
printf("Unspec: %d\n", i);
}
void OutI(signed int i)
{
printf("Signed: %d\n", i);
} void OutI(unsigned int i)
{
printf("Unsigned: %d\n", i);
}
Такие определения вызовут сообщение об ошибке компиляции, поскольку типы int и signed int эквивалентны.
Ссылки
В C++ имеется модифицированная форма указателей, называемая ссылкой (reference). Ссылка — это указатель, который автоматически разыменовывается при любом обращении к нему. Поэтому ссылке, как таковой, нельзя присвоить значение, как это можно сделать с обычным указателем. Ссылку можно только инициализировать.
Ссылки как псевдонимы переменных
Переменная-ссылка объявляется со знаком “&”, предшествующим ее имени; инициализирующим выражением должно быть имя переменной. Рассмотрите такой пример:
///////////////////////////////////////////////////////////////////
// Alias.cpp: Ссылка как псевдоним.
//
#include <stdio.h>
int main(void)
{
int iVar = 7777;
// Инициализация целой переменной.
int *iPtr = siVar;
// Инициализация указателя адресом
// iVar.
int &iRef = iVar;
// Инициализация ссылки как
// псевдонима iVar.
int *irPtr = &iRef;
// Инициализация указателя "адресом"
// ссылки.
printf("iVar = %d\n", iVar) ;
printf("*iPtr = %d\n", *iPtr);
printff'iRef = %d\n", iRef);
printf("*irPtr = %d\n", *irPtr) ;
printff'iPtr = %p, irPtr = %p\n", iPtr, irPtr);
return 0;
}
Первые четыре оператора printf выводят одно и то же число 7777. последний оператор печатает значения двух указателей, первый из которых инициализирован адресом переменной, а второй адресом ссылки. Эти адреса также оказываются одинаковыми. Как видите, после инициализации ссылки ее имя используется в точности как имя ассоциированной с ней переменной, т. е. как псевдоним.
Еще раз подчеркнем, что ссылку после инициализации нельзя изменить; все обращения к ссылке будут относиться на самом деле к переменной, именем которой она была инициализирована.
Ссылки в качестве параметров функции
Все сказанное в предыдущем параграфе не имеет существенного практического значения; к чему, в самом деле, вводить ссылку на переменную, если с тем же успехом можно обращаться к ней самой? По-иному дело обстоит в случае, когда ссылкой объявляется параметр функции.
Параметры функции мало чем отличаются от ее локальных автоматических переменных. Разница только в том, что они располагаются на стеке выше адреса в регистре ЕВР, а локальные переменные — ниже. Передача параметров при вызове функции эквивалентна созданию локальных переменных и инициализации их значениями соответствующих аргументов.
Это означает, что если объявить формальный параметр как ссылку, то при вызове он будет инициализирован в качестве псевдонима переменной-аргумента. Если говорить о конкретной реализации этого механизма, функции передается указатель на переменную, автоматически разыменуемый при обращении к нему в теле функции.
Тем самым параметры-ссылки делают возможной настоящую “передачу по ссылке” без использования явных указателей и адресов. Вот сравнение различных видов передачи параметров:
//////////////////////////////////////////////////
// RefPar.cpp: Передача параметров по ссылке.
//
#include <stdio.h>
void SwapVal(int x, int y)
// Передача значений.
{
int temp;
temp = x;
x = y;
у = temp;
}
void SwapPtr(int *x, int *y)
// Передача указателей.
{
int temp;
temp = *x;
*x = *y;
*y = temp;
}
void SwapRef(int &x, int &y)
// Передача ссылок.
{
int temp;
temp = x;
x = y;
y = temp;
}
int main(void)
(
int i = 11, i = 22;
printf("Initial values: i=%d,j=%d.\n", i,j ) ;
SwapVal(i, j);
printf ("After SwapVal():i = %d,j =%d.\n",i,j);
SwapPtr (&i, &j) ;
printf("After SwapPtr():i =%d,j=%d.\n",i,j);
SwapRef(i, j) ;
printf("After SwapRef():i =%d,j=%d.\n",i,j);
return 0;
Программа напечатает:
Initial values: i = 11, j = 22.
After SwapValO i = 11, j = 22.
After SwapPtr():i = 22, j = 11.
After SwapRef () i = 11, j =22.
Как и должно быть, функция SwapVal () не влияет на значения передаваемых ей переменных, поскольку она обменивает лишь локальные их копии. Функция SwapPtr () , принимающая указатели, обменивает значия исходных переменных, но требует явного указания адресов при вызове и явного их разыменования в теле переменной. Наконец, SwapRef () , с параметрами-ссылками, также обменивает значения переданных ей переменных. Причем она отличается от функции, принимающей параметры-значения, только заголовком. Тело SwapRef () и ее вызов выглядят совершенно аналогично функции SwapVal () .
Помимо случаев, когда функция должна возвращать значения в параметрах, ссылки могут быть полезны при передаче больших структур, поскольку функции тогда передается не сама структура, а ее адрес.
Передавая параметры по ссылке, нужно всегда помнить о возможных побочных эффектах. Если только функция не должна явно изменять значение своего аргумента, лучше объявить параметр как ссылку на константу (например, const int SiVal). Тогда при попытке присвоить параметру значение в теле функции компилятор выдаст сообщение об ошибке.
Ссылка в качестве возвращаемого значения
Возвращаемое функцией значение также может быть объявлено ссылкой. Это позволяет использовать функцию в левой части присваивания. Рассмотрите такой пример:
////////////////////////////////////////////////////////
// массива.
//
#include <stdio.h>
#include <assert.h>
const int arrSize = 8;
int &refItem(int indx)
// Возвращает ссылку на элемент
//
iArray[indx] {
static int iArray[arrSize];
//
// Проверка диапазона:
//
assert(indx >= 0 && indx< arrSize);
return iArray[indx];
}
int main(void) {
int i;
for (i=0; .KarrSise; i++)
refltem(i) = 1 << i;
// Присваивает значение элементу
// iArray[i].
for (i=O; i<arrSize; i++)
printf("iArray[%02d] = %4d\n'\ i, refltem(i));
refltem(i) = 0; // Попытка выхода за пределы
// массива.
return 0;
}
В первом из операторов for функция refltem() вызывается в левой части присваивания. Во втором for она возвращает значение, которое передается функции printf (). Обратите внимание, что, во-первых, массив iArray[] объявлен как статический локальный в refltem(), благодаря чему непосредственное обращение к нему вне этой функции невозможно. Во-вторых, refltem() попутно проверяет допустимость переданного ей индекса. Ссылка позволяет на элементарном уровне организовать механизм, который мы в следующей главе назовем сокрытием или абстрагированием данных.
Тип bool
В языке С и первых версиях C++ не было специального булева (логического) типа данных. В качестве логических использовались переменные целочисленных типов. В качестве истинного и ложного логических значений часто вводили символические константы, например:
#define FALSE0
#define TRUE 1
int done = FALSE;
while (!done) { // И т.д...
}
Теперь в ANSI C++ есть тип bool, позволяющий объявлять переменные специально булева типа. Кроме того, для представления булевых значений имеются предопределенные константы true и false. Внутренним представлением true является 1, представлением fal5e .— 0. С их помощью можно присваивать значения булевым переменным:
bool done;
const bool forever = true;
done = false;
Можно определять булевы функции, булевы параметры и т. п. Вот, например, прототип булевой функции с булевым параметром:
bool Continue(bool showPrompt);
В условиях циклов и выражениях условных операторов булевы переменные ведут себя точно так же, как прежние “логические” типа int.
Тип wchar_t
Это еще один новый встроенный тип C++. Он предназначен для хранения “широких” символов (в противоположность “узким” символам типа char). Тип wchar_t имеет достаточный диапазон, чтобы отображать очень большие наборы символов — вплоть до китайских иероглифов. В С++Вuilder он эквивалентен типу short int.
Указатели типа void*
В языке С значение типа void* можно непосредственно присваивать переменной-указателю любого типа, без каких-либо приведений. В C++ это не допускается. Другими словами, код вроде
SomeStruct *sPtr;
void AllocBuffer(int n)
{
sPtr = malloc(n * sizeof(SomeStruct));
}
вызовет ошибку в C++. Необходимо явное приведение типа указателя:
sPtr = (SomeStruct *)malloc(n * sizeof(SomeStruct));
“Улучшенный С”
В этом разделе мы рассмотрим те нововведения C++, которые можно считать усовершенствованиями С, поскольку они не выходят за рамки классической структурной модели программирования.
