Переменные
Программа оперирует информацией, представленной в виде различных объектов и величин. Переменная – это символическое обозначение величины в программе. Как ясно из названия, значение переменной (или величина, которую она обозначает) во время выполнения программы может изменяться.
С точки зрения архитектуры компьютера, переменная – это символическое обозначение ячейки оперативной памяти программы, в которой хранятся данные. Содержимое этой ячейки – это текущее значение переменной.
В языке Си++ прежде чем использовать переменную, ее необходимо объявить. Объявить переменную с именем x можно так:
int x;
В объявлении первым стоит название типа переменной int (целое число), а затем идентификатор x – имя переменной. У переменной x есть тип – в данном случае целое число. Тип переменной определяет, какие возможные значения эта переменная может принимать и какие операции можно выполнять над данной переменной. Тип переменной изменить нельзя, т.е. пока переменная x существует, она всегда будет целого типа.
Язык Си++ – это строго типизированный язык. Любая величина, используемая в программе, принадлежит к какому-либо типу. При любом использовании переменных в программе проверяется, применимо ли выражение или операция к типу переменной. Довольно часто смысл выражения зависит от типа участвующих в нем переменных.
Например, если мы запишем x+y, где x – объявленная выше переменная, то переменная y должна быть одного из числовых типов.
Соответствие типов проверяется во время компиляции программы. Если компилятор обнаруживает несоответствие типа переменной и ее использования, он выдаст ошибку (или предупреждение). Однако во время выполнения программы типы не проверяются. Такой подход, с одной стороны, позволяет обнаружить и исправить большое количество ошибок на стадии компиляции, а, с другой стороны, не замедляет выполнения программы.
Переменной можно присвоить какое-либо значение с помощью операции присваивания. Присвоить – это значит установить текущее значение переменной. По-другому можно объяснить, что операция присваивания запоминает новое значение в ячейке памяти, которая обозначена переменной.
int x; // объявить целую переменную x int y; // объявить целую переменную y x = 0; // присвоить x значение 0 y = x + 1; // присвоить y значение x + 1, // т.е. 1 x = 1; // присвоить x значение 1 y = x + 1; // присвоить y значение x + 1, // теперь уже 2
Арифметические операции
+ сложение - вычитание * умножение / деление
Операции сложения, вычитания, умножения и деления целых и вещественных чисел. Результат операции – число, по типу соответствующее большему по разрядности операнду. Например, сложение чисел типа short и long в результате дает число типа long.
% остаток
Операция нахождения остатка от деления одного целого числа на другое. Тип результата – целое число.
- минус + плюс
Операция "минус" – это унарная операция, при которой знак числа изменяется на противоположный. Она применима к любым числам со знаком. Операция "плюс" существует для симметрии. Она ничего не делает, т.е. примененная к целому числу, его же и выдает.
++ увеличить на единицу, префиксная и постфиксная формы -- уменьшить на единицу, префиксная и постфиксная формы
Эти операции иногда называют "автоувеличением" и "автоуменьшением". Они увеличивают (или, соответственно, уменьшают) операнд на единицу. Разница между постфиксной (знак операции записывается после операнда, например x++) и префиксной (знак операции записывается перед операндом, например --y) операциями заключается в том, что в первом случае результатом является значение операнда до изменения на единицу, а во втором случае – после изменения на единицу.
Битовые операции
битовое И | битовое ИЛИ ^ битовое ИСКЛЮЧАЮЩЕЕ ИЛИ ~ битовое НЕ
Побитовые операции над целыми числами. Соответствующая операция выполняется над каждым битом операндов. Результатом является целое число.
сдвиг влево сдвиг вправо
Побитовый сдвиг левого операнда на количество разрядов, соответствующее значению правого операнда. Результатом является целое число.
Логические операции
логическое И || логическое ИЛИ ! логическое НЕ
Логические операции конъюнкции, дизъюнкции и отрицания. В качестве операндов выступают логические значения, результат – тоже логическое значение true или false.
Операции сравнения
== равно != не равно меньше больше = меньше или равно = больше или равно
Операции сравнения. Сравнивать можно операнды любого типа, но либо они должны быть оба одного и того же встроенного типа (сравнение на равенство и неравенство работает для двух величин любого типа), либо между ними должна быть определена соответствующая операция сравнения. Результат – логическое значение true или false.
Операция присваивания
Присваивание – это тоже операция, она является частью выражения. Значение правого операнда присваивается левому операнду.
x = 2; // переменной x присвоить значение 2 cond = x 2; // переменной cond присвоить значение true, если x меньше 2, // в противном случае присвоить значение false 3 = 5; // ошибка, число 3 неспособно изменять свое значение
Последний пример иллюстрирует требование к левому операнду операции присваивания. Он должен быть способен хранить и изменять свое значение. Переменные, объявленные в программе, обладают подобным свойством. В следующем фрагменте программы
int x = 0; x = 3; x = 4; x = x + 1;
вначале объявляется переменная x с начальным значением 0. После этого значение x изменяется на 3, 4 и затем 5. Опять-таки, обратим внимание на последнюю строчку. При вычислении операции присваивания сначала вычисляется правый операнд, а затем левый. Когда вычисляется выражение x + 1, значение переменной x равно 4. Поэтому значение выражения x + 1 равно 5. После вычисления операции присваивания (или, проще говоря, после присваивания) значение переменной x становится равным 5.
У операции присваивания тоже есть результат. Он равен значению левого операнда. Таким образом, операция присваивания может участвовать в более сложном выражении:
z = (x = y + 3);
В приведенном примере переменным x и z присваивается значение y + 3.
Очень часто в программе приходится значение переменной увеличивать или уменьшать на единицу. Для того чтобы сделать эти действия наиболее эффективными и удобными для использования, применяются предусмотренные в Си++ специальные знаки операций: ++ (увеличить на единицу) и -- (уменьшить на единицу). Существует две формы этих операций: префиксная и постфиксная. Рассмотрим их на примерах.
int x = 0; ++x;
Значение x увеличивается на единицу и становится равным 1.
--x;
Значение x уменьшается на единицу и становится равным 0.
int y = ++x;
Значение x опять увеличивается на единицу. Результат операции ++ – новое значение x, т.е. переменной y присваивается значение 1.
int z = x++;
Здесь используется постфиксная запись операции увеличения на единицу. Значение переменной x до выполнения операции равно 1. Сама операция та же – значение x увеличивается на единицу и становится равным 2. Однако результат постфиксной операции – значение аргумента до увеличения. Таким образом, переменной z присваивается значение 1. Аналогично, результатом постфиксной операции уменьшения на единицу является начальное значение операнда, а префиксной – его конечное значение.
Подобными мотивами оптимизации и сокращения записи руководствовались создатели языка Си (а затем и Си++), когда вводили новые знаки операций типа "выполнить операцию и присвоить". Довольно часто одна и та же переменная используется в левой и правой части операции присваивания, например:
x = x + 5; y = y * 3; z = z – (x + y);
В Си++ эти выражения можно записать короче:
x += 5; y *= 3; z -= x + y;
Т.е. запись oper= означает, что левый операнд вначале используется как левый операнд операции oper, а затем как левый операнд операции присваивания результата операции oper. Кроме краткости выражения, такая запись облегчает оптимизацию программы компилятором.
on_load_lecture()

/p> |
/p> |
/p> |
вопросы |
|
учебники
|
для печати и PDA
|
Курсы | Учебные программы | Учебники | Новости | Форум | Помощь Телефон: +7 (495) 253-9312, 253-9313, факс: +7 (495) 253-9310, email: info@intuit.ru 2003-2007, INTUIT.ru::Интернет-Университет Информационных Технологий - дистанционное образование |
Порядок вычисления выражений
У каждой операции имеется приоритет. Если в выражении несколько операций, то первой будет выполнена операция с более высоким приоритетом. Если же операции одного и того же приоритета, они выполняются слева направо.
Например, в выражении
+ 3 * 6
сначала будет выполнено умножение, а затем сложение;соответственно, значение этого выражения — число 20.
В выражении
* 3 + 4 * 5
сначала будет выполнено умножение, а затем сложение. В каком порядке будет производиться умножение – сначала 2 * 3, а затем 4 * 5 или наоборот, не определено. Т.е. для операции сложения порядок вычисления ее операндов не задан.
В выражении
x = y + 3
вначале выполняется сложение, а затем присваивание, поскольку приоритет операции присваивания ниже, чем приоритет операции сложения.
Для данного правила существует исключение: если в выражении несколько операций присваивания, то они выполняются справа налево. Например, в выражении
x = y = 2
сначала будет выполнена операция присваивания значения 2 переменной y. Затем результат этой операции – значение 2 – присваивается переменной x.
Ниже приведен список всех операций в порядке понижения приоритета. Операции с одинаковым приоритетом выполняются слева направо (за исключением нескольких операций присваивания).
:: (разрешение области видимости имен)
. (обращение к элементу класса), - (обращение к элементу класса по указателю), [] (индексирование), вызов функции, ++ (постфиксное увеличение на единицу), -- (постфиксное уменьшение на единицу), typeid (нахождение типа), dynamic_cast static_cast reinterpret_cast const_cast (преобразования типа)
sizeof (определение размера), ++ (префиксное увеличение на единицу), -- (префиксное уменьшение на единицу), ~ (битовое НЕ), ! (логическое НЕ), – (изменение знака), + (плюс), (взятие адреса), * (обращение по адресу), new (создание объекта), delete (удаление объекта), (type) (преобразование типа)
.* -* (обращение по указателю на элемент класса)
* (умножение), / (деление), % (остаток)
+ (сложение), – (вычитание)
, (сдвиг)
= = (сравнения на больше или меньше)
== != (равно, неравно)
(поразрядное И)
^ (поразрядное исключающее ИЛИ)
| (поразрядное ИЛИ)
(логическое И)
|| (логическое ИЛИ)
= (присваивание), *= /= %= += -= = = = |= ^= (выполнить операцию и присвоить)
?: (условная операция)
throw
, (последовательность)
Для того чтобы изменить последовательность вычисления выражений, можно воспользоваться круглыми скобками. Часть выражения, заключенная в скобки, вычисляется в первую очередь. Значением
(2 + 3) * 6
будет 30.
Скобки могут быть вложенными, соответственно, самые внутренние выполняются первыми:
(2 + (3 * (4 + 5) ) – 2)
on_load_lecture()
|
/p> |
/p> |
/p> |
вопросы |
|
учебники
|
для печати и PDA
|
Курсы | Учебные программы | Учебники | Новости | Форум | Помощь Телефон: +7 (495) 253-9312, 253-9313, факс: +7 (495) 253-9310, email: info@intuit.ru 2003-2007, INTUIT.ru::Интернет-Университет Информационных Технологий - дистанционное образование |
Последовательность
, последовательность
Выполнить выражение до запятой, затем выражение после запятой. Два произвольных выражения можно поставить рядом, разделив их запятой. Они будут выполняться последовательно, и результатом всего выражения будет результат последнего выражения.
Условная операция
? : условное выражение
Тернарная операция; если значение первого операнда – истина, то результат – второй операнд; если ложь – результат – третий операнд. Первый операнд должен быть логическим значением, второй и третий операнды могут быть любого, но одного и того же, типа, а результат будет того же типа, что и третий операнд.
Все операции языка Си++
Наряду с общепринятыми арифметическими и логическими операциями, в языке Си++ имеется набор операций для работы с битами – поразрядные И, ИЛИ, ИСКЛЮЧАЮЩЕЕ ИЛИ и НЕ, а также сдвиги.
Особняком стоит операция sizeof. Эта операция позволяет определить, сколько памяти занимает то или иное значение. Например:
sizeof(long); // сколько байтов занимает тип long
sizeof (b); // сколько байтов занимает переменная b
Операция sizeof в качестве аргумента берет имя типа или выражение. Аргумент заключается в скобки (если аргумент – выражение, скобки не обязательны). Результат операции – целое число, равное количеству байтов, которое необходимо для хранения в памяти заданной величины.
Ниже приводятся все операции языка Си++.
Выражения
Программа оперирует с данными. Числа можно складывать, вычитать, умножать, делить. Из разных величин можно составлять выражения, результат вычисления которых – новая величина. Приведем примеры выражений:
X * 12 + Y // значение X умножить на 12 и к результату прибавить значение Y val 3 // сравнить значение val с 3 -9 // константное выражение -9
Выражение, после которого стоит точка с запятой – это оператор-выражение. Его смысл состоит в том, что компьютер должен выполнить все действия, записанные в данном выражении, иначе говоря, вычислить выражение.
x + y – 12; // сложить значения x и y и затем вычесть 12 a = b + 1; // прибавить единицу к значению b и запомнить результат в переменной a
Выражения – это переменные, функции и константы, называемые операндами, объединенные знаками операций. Операции могут быть унарными – с одним операндом, например, минус; могут быть бинарные – с двумя операндами, например сложение или деление. В Си++ есть даже одна операция с тремя операндами – условное выражение. Чуть позже мы приведем список всех операций языка Си++ для встроенных типов данных. Подробно каждая операция будет разбираться при описании соответствующего типа данных. Кроме того, ряд операций будет рассмотрен в разделе, посвященном определению операторов для классов. Пока что мы ограничимся лишь общим описанием способов записи выражений.
В типизированном языке, которым является Си++, у переменных и констант есть определенный тип. Есть он и у результата выражения. Например, операции сложения (+), умножения (*), вычитания (-) и деления (/), примененные к целым числам, выполняются по общепринятым математическим правилам и дают в результате целое значение. Те же операции можно применить к вещественным числам и получить вещественное значение.
Операции сравнения: больше (), меньше (), равно (==), не равно (!=) сравнивают значения чисел и выдают логическое значение: истина (true) или ложь (false).
Что такое оператор
Запись действий, которые должен выполнить компьютер, состоит из операторов. При выполнении программы операторы выполняются один за другим, если только оператор не является оператором управления, который может изменить последовательное выполнение программы.
Различают операторы объявления имен, операторы управления и операторы-выражения.
Оператор возврата
Оператор return завершает выполнение функции и возвращает управление в ту точку, откуда она была вызвана. Его форма:
return выражение;
Где выражение – это результат функции. Если функция не возвращает никакого значения, то оператор возврата имеет форму
return;
Операторы цикла
Предположим, нам нужно вычислить сумму всех целых чисел от 0 до 100. Для этого воспользуемся оператором цикла for:
int sum = 0; int i; for (i = 1; i = 100; i = i + 1) // заголовок цикла sum = sum + i; // тело цикла
Оператор цикла состоит из заголовка цикла и тела цикла. Тело цикла – это оператор, который будет повторно выполняться (в данном случае – увеличение значения переменной sum на величину переменной i). Заголовок – это ключевое слово for, после которого в круглых скобках записаны три выражения, разделенные точкой с запятой. Первое выражение вычисляется один раз до начала выполнения цикла. Второе – это условие цикла. Тело цикла будет повторяться до тех пор, пока условие цикла истинно. Третье выражение вычисляется после каждого повторения тела цикла.
Оператор for реализует фундаментальный принцип вычислений в программировании – итерацию. Тело цикла повторяется для разных, в данном случае последовательных, значений переменной i. Повторение иногда называется итерацией. Мы как бы проходим по последовательности значений переменной i, выполняя с текущим значением одно и то же действие, тем самым постепенно вычисляя нужное значение. С каждой итерацией мы подходим к нему все ближе и ближе. С другим принципом вычислений в программировании – рекурсией – мы познакомимся в разделе, описывающем функции.
Любое из трех выражений в заголовке цикла может быть опущено (в том числе и все три). То же самое можно записать следующим образом:
int sum = 0; int i = 1; for (; i = 100; ) { sum = sum + i; i = i + 1; }
Заметим, что вместо одного оператора цикла мы записали несколько операторов, заключенных в фигурные скобки – блок. Другой вариант:
int sum = 0; int i = 1; for (; ;) { if (i 100) break; sum = sum + i; i = i + 1; }
В последнем примере мы опять встречаем оператор break. Оператор break завершает выполнение цикла. Еще одним вспомогательным оператором при выполнении циклов служит оператор продолжения continue. Оператор continue заставляет пропустить остаток тела цикла и перейти к следующей итерации (повторению). Например, если мы хотим найти сумму всех целых чисел от 0 до 100, которые не делятся на 7, можно записать это так:
int sum = 0; for (int i = 1; i = 100; i = i+1) { if ( i % 7 == 0) continue; sum = sum + i; }
Еще одно полезное свойство цикла for: в первом выражении заголовка цикла можно объявить переменную. Эта переменная будет действительна только в пределах цикла.
Другой формой оператора цикла является оператор while. Его форма следующая:
while (условие) оператор
Условие – как и в условном операторе if – это выражение, которое принимает логическое значение "истина" или "ложь". Выполнение оператора повторяется до тех пор, пока значением условия является true (истина). Условие вычисляется заново перед каждой итерацией. Подсчитать, сколько десятичных цифр нужно для записи целого положительного числа N, можно с помощью следующего фрагмента:
int digits =0; while (N 0) { digits = digits + 1; N = N / 10; }
Третьей формой оператора цикла является цикл do while. Он имеет форму:
do { операторы } while ( условие);
Отличие от предыдущей формы цикла while заключается в том, что условие проверяется после выполнения тела цикла. Предположим, требуется прочитать символы с терминала до тех пор, пока не будет введен символ "звездочка".
char ch; do { ch = getch(); // функция getch возвращает // символ, введёный с // клавиатуры } while (ch != '*');
В операторах while и do также можно использовать операторы break и continue.
Как легко заметить, операторы цикла взаимозаменяемы. Оператор while соответствует оператору for:
for ( ; условие ; ) оператор
Пример чтения символов с терминала можно переписать в виде:
char ch; ch = getch(); while (ch != '*') { ch = getch(); }
Разные формы нужны для удобства и наглядности записи.
Операторы управления
Операторы управления определяют, в какой последовательности выполняется программа. Если бы их не было, операторы программы всегда выполнялись бы последовательно, в том порядке, в котором они записаны.
Операторы-выражения
Выражения мы рассматривали в предыдущей лекции. Выражение, после которого стоит точка с запятой, – это оператор-выражение. Его смысл состоит в том, что компьютер должен выполнить все действия, записанные в данном выражении, иначе говоря, вычислить выражение. Чаще всего в операторе-выражении стоит операция присваивания или вызов функции. Операторы выполняются последовательно, и все изменения значений переменных, сделанные в предыдущем операторе, используются в последующих.
a = 1; b = 3; m = max(a, b);
Переменной a присваивается значение 1, переменной b – значение 3. Затем вызывается функция max с параметрами 1 и 3, и ее результат присваивается переменной m.
Как мы уже отмечали, присваивание – необязательная операция в операторе-выражении. Следующие операторы тоже вполне корректны:
x + y – 12; // сложить значения x и y и // затем вычесть 12 func(d, 12, x); // вызвать функцию func с // заданными параметрами
Условные операторы
Условные операторы позволяют выбрать один из вариантов выполнения действий в зависимости от каких-либо условий. Условие – это логическое выражение, т.е. выражение, результатом которого является логическое значение true (истина) или false (ложь).
Оператор if выбирает один из двух вариантов последовательности вычислений.
if (условие) оператор1 else оператор2
Если условие истинно, выполняется оператор1, если ложно, то выполняется оператор2.
if (x y) a = x; else a = y;
В данном примере переменной a присваивается значение максимума из двух величин x и y.
Конструкция else необязательна. Можно записать:
if (x 0) x = -x; abs = x;
В данном примере оператор x = -x; выполняется только в том случае, если значение переменной x было отрицательным. Присваивание переменной abs выполняется в любом случае. Таким образом, приведенный фрагмент программы изменит значение переменной x на его абсолютное значение и присвоит переменной abs новое значение x.
Если в случае истинности условия необходимо выполнить несколько операторов, их можно заключить в фигурные скобки:
if (x 0) { x = -x; cout "Изменить значение x на противоположное по знаку"; } abs = x;
Теперь если x отрицательно, то не только его значение изменится на противоположное, но и будет выведено соответствующее сообщение. Фактически, заключая несколько операторов в фигурные скобки, мы сделали из них один сложный оператор или блок. Прием заключения нескольких операторов в блок работает везде, где нужно поместить несколько операторов вместо одного.
Условный оператор можно расширить для проверки нескольких условий:
if (x 0) cout "Отрицательная величина"; else if (x 0) cout "Положительная величина"; else cout "Ноль";
Конструкций else if может быть несколько.
Хотя любые комбинации условий можно выразить с помощью оператора if, довольно часто запись становится неудобной и запутанной. Оператор выбора switch используется, когда для каждого из нескольких возможных значений выражения нужно выполнить определенные действия. Например, предположим, что в переменной code хранится целое число от 0 до 2, и нам нужно выполнить различные действия в зависимости от ее значения:
switch (code) { case 0: cout "код ноль"; x = x + 1; break; case 1 : cout "код один"; y = y + 1; break; case 2: cout "код два"; z = z + 1; break; default: cout "Необрабатываемое значение"; }
В зависимости от значения code управление передается на одну из меток case. Выполнение оператора заканчивается по достижении либо оператора break, либо конца оператора switch. Таким образом, если code равно 1, выводится "код один", а затем переменная y увеличивается на единицу. Если бы после этого не стоял оператор break, то управление "провалилось" бы дальше, была бы выведена фраза "код два", и переменная z тоже увеличилась бы на единицу.
Если значение переключателя не совпадает ни с одним из значений меток case, то выполняются операторы, записанные после метки default. Метка default может быть опущена, что эквивалентно записи:
default: ; // пустой оператор, не выполняющий // никаких действий
Очевидно, что приведенный пример можно переписать с помощью оператора if:
if (code == 0) { cout "код ноль"; x = x + 1; } else if (code == 1) { cout "код один"; y = y + 1; } else if (code == 2) { cout "код два"; z = z + 1; } else { cout "Необрабатываемое значение"; }
Пожалуй, запись с помощью оператора переключения switch более наглядна. Особенно часто переключатель используется, когда значение выражения имеет тип набора.
Имена функций
В языке Си++ допустимо иметь несколько функций с одним и тем же именем, потому что функции различаются не только по именам, но и по типам аргументов. Если в дополнение к определенной выше функции sum мы определим еще одну функцию с тем же именем
double sum(double a, double b, double c) { double result; result = a + b + c; return result; }
это будет считаться новой функцией. Иногда говорят, что у этих функций разные подписи. В следующем фрагменте программы в первый раз будет вызвана первая функция, а во второй раз – вторая:
int x, y, z, ires; double p,q,s, dres; . . . // вызвать первое определение функции sum ires = sum(x,y,z); // вызвать второе определение функции sum dres = sum(p,q,s);
При первом вызове функции sum все фактические аргументы имеют тип int. Поэтому вызывается первая функция. Во втором вызове все аргументы имеют тип double, соответственно, вызывается вторая функция.
Важен не только тип аргументов, но и их количество. Можно определить функцию sum, суммирующую четыре аргумента:
int sum(int x1, int x2, int x3, int x4) { return x1 + x2 + x3 + x4; }
Отметим, что при определении функций имеют значение тип и количество аргументов, но не тип возвращаемого значения. Попытка определения двух функций с одним и тем же именем, одними и теми же аргументами, но разными возвращаемыми значениями, приведет к ошибке компиляции:
int foo(int x); double foo(int x); // ошибка – двукратное определение имени
Рекурсия
Определения функций не могут быть вложенными, т.е. нельзя внутри тела одной функции определить тело другой. Разумеется, можно вызвать одну функцию из другой. В том числе функция может вызвать сама себя.
Рассмотрим функцию вычисления факториала целого числа. Ее можно реализовать двумя способами. Первый способ использует итерацию:
int fact(int n) { int result = 1; for (int i = 1; i = n; i++) result = result * i; return result; }
Второй способ:
int fact(int n) { if (n == 1) // факториал 1 равен 1 return 1; else // факториал числа n равен // факториалу n-1 // умноженному на n
return n * fact(n -1); }
Функция fact вызывает сама себя с модифицированными аргументами. Такой способ вычислений называется рекурсией. Рекурсия – это очень мощный метод вычислений. Значительная часть математических функций определяется в рекурсивных терминах. В программировании алгоритмы обработки сложных структур данных также часто бывают рекурсивными. Рассмотрим, например, структуру двоичного дерева. Дерево состоит из узлов и направленных связей. С каждым узлом могут быть связаны один или два узла, называемые сыновьями этого узла. Соответственно, для "сыновей" узел, из которого к ним идут связи, называется "отцом". Узел, у которого нет "отца", называется корнем. У дерева есть только один корень. Узлы, у которых нет "сыновей", называются листьями. Пример дерева приведен на 5.1.
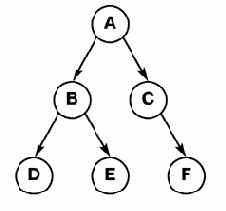
5.1. Пример дерева.
В этом дереве узел A – корень дерева, узлы B и C – "сыновья" узла A, узлы D и E – "сыновья" узла B, узел F – "сын" узла C. Узлы D, E и F – листья. Узел B является корнем поддерева, состоящего из трех узлов B, D и E. Обход дерева (прохождение по всем его узлам) можно описать таким образом:
Посетить корень дерева. Обойти поддеревья с корнями — "сыновьями" данного узла, если у узла есть "сыновья". Если у узла нет "сыновей" — обход закончен.
Очевидно, что реализация такого алгоритма с помощью рекурсии не составляет труда.
Довольно часто рекурсия и итерация взаимозаменяемы (как в примере с факториалом). Выбор между ними может быть обусловлен разными факторами. Чаще рекурсия более наглядна и легче реализуется. Однако, в большинстве случаев итерация более эффективна.
Вызов функций
Функция вызывается при вычислении выражений. При вызове ей передаются определенные аргументы, функция выполняет необходимые действия и возвращает результат.
Программа на языке Си++ состоит, по крайней мере, из одной функции – функции main. С нее всегда начинается выполнение программы. Встретив имя функции в выражении, программа вызовет эту функцию, т.е. передаст управление на ее начало и начнет выполнять операторы. Достигнув конца функции или оператора return – выхода из функции, управление вернется в ту точку, откуда функция была вызвана, подставив вместо нее вычисленный результат.
Прежде всего, функцию необходимо объявить. Объявление функции, аналогично объявлению переменной, определяет имя функции и ее тип – типы и количество ее аргументов и тип возвращаемого значения.
// функция sqrt с одним аргументом – // вещественным числом двойной точности, // возвращает результат типа double
double sqrt(double x); // функция sum от трех целых аргументов // возвращает целое число int sum(int a, int b, int c);
Объявление функции называют иногда прототипом функции. После того, как функция объявлена, ее можно использовать в выражениях:
double x = sqrt(3) + 1; sum(k, l, m) / 15;
Если функция не возвращает никакого результата, т.е. она объявлена как void, ее вызов не может быть использован как операнд более сложного выражения, а должен быть записан сам по себе:
func(a,b,c);
Определение функции описывает, как она работает, т.е. какие действия надо выполнить, чтобы получить искомый результат. Для функции sum, объявленной выше, определение может выглядеть следующим образом:
int sum(int a, int b, int c) { int result; result = a + b + c; return result; }
Первая строка – это заголовок функции, он совпадает с объявлением функции, за исключением того, что объявление заканчивается точкой с запятой. Далее в фигурных скобках заключено тело функции – действия, которые данная функция выполняет.
Аргументы a, b и c называются формальными параметрами. Это переменные, которые определены в теле функции (т.е. к ним можно обращаться только внутри фигурных скобок). При написании определения функции программа не знает их значения. При вызове функции вместо них подставляются фактические параметры – значения, с которыми функция вызывается. Выше, в примере вызова функции sum, фактическими параметрами ( или фактическими аргументами) являлись значения переменных k, l и m.
Формальные параметры принимают значения фактических аргументов, заданных при вызове, и функция выполняется.
Первое, что мы делаем в теле функции — объявляем внутреннюю переменную result типа целое. Переменные, объявленные в теле функции, также называют локальными. Это связано с тем, что переменная result существует только во время выполнения тела функции sum. После завершения выполнения функции она уничтожается – ее имя становится неизвестным, и память, занимаемая этой переменной, освобождается.
Вторая строка определения тела функции – вычисление результата. Сумма всех аргументов присваивается переменной result. Отметим, что до присваивания значение result было неопределенным (то есть значение переменной было неким произвольным числом, которое нельзя определить заранее).
Последняя строчка функции возвращает в качестве результата вычисленное значение. Оператор return завершает выполнение функции и возвращает выражение, записанное после ключевого слова return, в качестве выходного значения. В следующем фрагменте программы переменной s присваивается значение 10:
Целые числа
Для представления целых чисел в языке Си++ существует несколько типов – char, short, int и long (полное название типов: short int, long int, unsigned long int и т.д.. Поскольку описатель int можно опустить, мы используем сокращенные названия). Они отличаются друг от друга диапазоном возможных значений. Каждый из этих типов может быть знаковым или беззнаковым. По умолчанию, тип целых величин – знаковый. Если перед определением типа стоит ключевое слово unsigned , то тип целого числа — беззнаковый. Для того чтобы определить переменную x типа короткого целого числа, нужно записать:
short x;
Число без знака принимает только положительные значения и значение ноль. Число со знаком принимает положительные значения, отрицательные значения и значение ноль.
Целое число может быть непосредственно записано в программе в виде константы. Запись чисел соответствует общепринятой нотации. Примеры целых констант: 0, 125, -37. По умолчанию целые константы принадлежат к типу int. Если необходимо указать, что целое число — это константа типа long , можно добавить символ L или l после числа. Если константа беззнаковая, т.е. относится к типу unsigned long или unsigned int , после числа записывается символ U или u. Например: 34U, 700034L, 7654ul.
Кроме стандартной десятичной записи, числа можно записывать в восьмеричной или шестнадцатеричной системе счисления. Признаком восьмеричной системы счисления является цифра 0 в начале числа. Признаком шестнадцатеричной — 0x или 0X перед числом. Для шестнадцатеричных цифр используются латинские буквы от A до F (неважно, большие или маленькие).
Таким образом, фрагмент программы
const int x = 240; const int y = 0360; const int z = 0x0F0;
определяет три целые константы x, y и z с одинаковыми значениями.
Отрицательные числа предваряются знаком минус "-". Приведем еще несколько примеров:
// ошибка в записи восьмеричного числа const unsigned long ll = 0678; // правильная запись const short a = 0xa4; // ошибка в записи десятичного числа const int x = 23F3;
Для целых чисел определены стандартные арифметические операции сложения (+), вычитания (-), умножения (*), деления (/); нахождение остатка от деления (%), изменение знака (-). Результатом этих операций также является целое число. При делении остаток отбрасывается. Примеры выражений с целыми величинами:
x + 4; 30 — x; x * 2; -x; 10 / x; x % 3;
Кроме стандартных арифметических операций, для целых чисел определен набор битовых (или поразрядных) операций. В них целое число рассматривается как строка битов (нулей и единиц при записи числа в двоичной системе счисления или разрядов машинного представления).
К этим операциям относятся поразрядные операции И, ИЛИ, ИСКЛЮЧАЮЩЕЕ ИЛИ, поразрядное отрицание и сдвиги. Поразрядная операция ИЛИ, обозначаемая знаком |, выполняет операцию ИЛИ над каждым индивидуальным битом двух своих операндов. Например, 1 | 2 в результате дают 3, поскольку в двоичном виде 1 это 01, 2 – это 10, соответственно, операция ИЛИ дает 11 или 3 в десятичной системе (нули слева мы опустили).
Аналогично выполняются поразрядные операции И, ИСКЛЮЧАЮЩЕЕ ИЛИ и отрицание.
| 1 результат 3 4 7 результат 4 4 ^ 7 результат 3 0 0xF результат 0 ~0x00F0 результат 0xFF0F
Операция сдвига перемещает двоичное представление левого операнда на количество битов, соответствующее значению правого операнда. Например, двоичное представление короткого целого числа 3 – 0000000000000011. Результатом операции 3 2 (сдвиг влево) будет двоичное число 0000000000001100 или, в десятичной записи, 12. Аналогично, сдвинув число 9 (в двоичном виде 0000000000001001) на 2 разряда вправо (записывается 9 2) получим 0000000000000010, т.е. 2.
При сдвиге влево число дополняется нулями справа. При сдвиге вправо бит, которым дополняется число, зависит от того, знаковое оно или беззнаковое. Для беззнаковых чисел при сдвиге вправо они всегда дополняются нулевым битом. Если же число знаковое, то значение самого левого бита числа используется для дополнения. Это объясняется тем, что самый левый бит как раз и является знаком — 0 означает плюс и 1 означает минус. Таким образом, если
short x = 0xFF00; unsigned short y = 0xFF00;
то результатом x 2 будет 0xFFC0 (двоичное представление 1111111111000000), а результатом y 2 будет 0x3FC0 (двоичное представление 0011111111000000).
Рассмотренные арифметические и поразрядные операции выполняются над целыми числами и в результате дают целое число. В отличие от них операции сравнения выполняются над целыми числами, но в результате дают логическое значение истина ( true ) или ложь ( false ).
Для целых чисел определены операции сравнения: равенства (==), неравенства (!=), больше (), меньше (), больше или равно (=) и меньше или равно (=).
Последний вопрос, который мы рассмотрим в отношении целых чисел, – это преобразование типов. В языке Си++ допустимо смешивать в выражении различные целые типы. Например, вполне допустимо записать x + y, где x типа short , а y – типа long . При выполнении операции сложения величина переменной x преобразуется к типу long . Такое преобразование можно произвести всегда, и оно безопасно, т.е. мы не теряем никаких значащих цифр. Общее правило преобразования целых типов состоит в том, что более короткий тип при вычислениях преобразуется в более длинный. Только при выполнении присваивания длинный тип может преобразовываться в более короткий. Например:
short x; long y = 15; . . . x = y; // преобразование длинного типа // в более короткий
Такое преобразование не всегда безопасно, поскольку могут потеряться значащие цифры. Обычно компиляторы, встречая такое преобразование, выдают предупреждение или сообщение об ошибке.
Кодировка, многобайтовые символы
Мы уже упоминали о наличии разных кодировок букв, цифр, знаков препинания и т.д. Алфавит большинства европейских языков может быть представлен однобайтовыми числами (т.е. кодами в диапазоне от 0 до 255). В большинстве кодировок принято, что первые 127 кодов отводятся для символов, входящих в набор ASCII: ряд специальных символов, латинские заглавные и строчные буквы, арабские цифры и знаки препинания. Вторая половина кодов – от 128 до 255 отводится под буквы того или иного языка. Фактически, вторая половина кодовой таблицы интерпретируется по-разному, в зависимости от того, какой язык считается "текущим". Один и тот же код может соответствовать разным символам в зависимости от того, какой язык считается "текущим".
Однако для таких языков, как китайский, японский и некоторые другие, одного байта недостаточно – алфавиты этих языков насчитывают более 255 символов.
Перечисленные выше проблемы привели к созданию многобайтовых кодировок символов. Двухбайтовые символы в языке Си++ представляются с помощью типа wchar_t
:
wchar_t wch;
Тип wchar_t иногда называют расширенным типом символов, и детали его реализации могут варьироваться от компилятора к компилятору, в том числе может меняться и количество байт, которое отводится под один символ. Тем не менее, в большинстве случаев используется именно двухбайтовое представление.
Константы типа wchar_t записываются в виде L'ab'.
Общая информация
Встроенные типы данных предопределены в языке. Это самые простые величины, из которых составляют все производные типы, в том числе и классы. Различные реализации и компиляторы могут определять различные диапазоны значений целых и вещественных чисел.
В таблице 6.1 перечислены простейшие типы данных, которые определяет язык Си++, и приведены наиболее типичные диапазоны их значений.
Таблица 6.1.
Встроенные типы языка Си++.
НазваниеОбозначениеДиапазон значений| Байт |
char | от -128 до +127 |
| без знака |
unsigned char | от 0 до 255 |
| Короткое целое число |
short | от -32768 до +32767 |
| Короткое целое число без знака |
unsigned short | от 0 до 65535 |
| Целое число |
int | от – 2147483648 до + 2147483647 |
| Целое число без знака |
unsigned int (или просто unsigned) | от 0 до 4294967295 |
| Длинное целое число |
long | от – 2147483648 до + 2147483647 |
| Длинное целое число без знака |
unsigned long | от 0 до 4294967295 |
| Вещественное число одинарной точности |
float | от ±3.4e-38 до ±3.4e+38 (7 значащих цифр) |
| Вещественное число двойной точности |
double | от ±1.7e-308 до ±1.7e+308 (15 значащих цифр) |
| Вещественное число увеличенной точности |
long double | от ±1.2e-4932 до ±1.2e+4932 |
| Логическое значение |
bool | значения true(истина) или false (ложь) |
Символы и байты
Символьный или байтовый тип в языке Си++ относится к целым числам, однако мы выделили их в особый раздел, потому что запись знаков имеет свои отличия.
Итак, для записи знаков в языке Си++ служат типы char и unsigned char . Первый – это целое число со знаком, хранящееся в одном байте, второй – беззнаковое байтовое число. Эти типы чаще всего используются для манипулирования символами, поскольку коды символов как раз помещаются в байт.
Пояснение. Единственное, что может хранить компьютер, это числа. Поэтому для того чтобы можно было хранить символы и манипулировать ими, символам присвоены коды – целые числа. Существует несколько стандартов, определяющих, какие коды каким символам соответствуют. Для английского алфавита и знаков препинания используется стандарт ASCII. Этот стандарт определяет коды от 0 до 127. Для представления русских букв используется стандарт КОИ-8 или CP-1251. В этих стандартах русские буквы кодируются числами от 128 до 255. Таким образом, все символы могут быть представлены в одном байте (максимальное число символов в одном байте – 255). Для работы с китайским, японским, корейским и рядом других алфавитов одного байта недостаточно, и используется кодировка с помощью двух байтов и, соответственно, тип wchar_t (подробнее см. ниже).
Чтобы объявить переменную байтового типа, нужно записать:
char c; // байтовое число со знаком
unsigned char u; // байтовое число без знака
Поскольку байты – это целые числа, то все операции с целыми числами применимы и к байтам. Стандартная запись целочисленных констант тоже применима к байтам, т.е. можно записать:
c = 45;
где c — байтовая переменная. Однако для байтов существует и другая запись констант. Знак алфавита (буква, цифра, знак препинания), заключенный в апострофы, представляет собой байтовую константу, например:
'S' '' '8' 'ф'
Числовым значением такой константы является код данного символа, принятый в Вашей операционной системе.
В кодировке ASCII два следующих оператора эквивалентны:
char c = 68; char c = 'D';
Первый из них присваивает байтовой переменной c значение числа 68. Второй присваивает этой переменной код латинской буквы D, который в кодировке ASCII равен 68.
Для обозначения ряда непечатных символов используются так называемые экранированные последовательности – знак обратной дробной черты, после которого стоит буква. Эти последовательности стандартны и заранее предопределены в языке:
\a звонок \b возврат на один символ назад \f перевод страницы \n новая строка \r перевод каретки \t горизонтальная табуляция \v вертикальная табуляция \' апостроф \" двойные кавычки \\ обратная дробная черта \? вопросительный знак
Для того чтобы записать произвольное байтовое значение, также используется экранированная последовательность: после обратной дробной черты записывается целое число от 0 до 255.
char zero = '\0'; const unsigned char bitmask = '\0xFF'; char tab = '\010';
Следующая программа выведет все печатные символы ASCII и их коды в порядке увеличения:
for (char c = 32; c 127; c++) cout c " " (int)c " ";
Однако напомним еще раз, что байтовые величины – это, прежде всего, целые числа, поэтому вполне допустимы выражения вида
'F' + 1 'a' 23
и тому подобные. Тип char был придуман для языка Си, от которого Си++ достались все базовые типы данных. Язык Си предназначался для программирования на достаточно "низком" уровне, приближенном к тому, как работает процессор ЭВМ, именно поэтому символ в нем – это лишь число.
В языке Си++ в большинстве случаев для работы с текстом используются специально разработанные классы строк, о которых мы будем говорить позже.
Вещественные числа
Вещественные числа в Си++ могут быть одного из трех типов: с одинарной точностью — float , с двойной точностью – double , и с расширенной точностью – long double.
float x; double e = 2.9; long double s;
В большинстве реализаций языка представление и диапазоны значений соответствуют стандарту IEEE (Institute of Electrical and Electronics Engineers) для представления вещественных чисел. Точность представления чисел составляет 7 десятичных значащих цифр для типа float , 15 значащих цифр для double и 19 — для типа long double .
Вещественные числа записываются либо в виде десятичных дробей, например 1.3, 3.1415, 0.0005, либо в виде мантиссы и экспоненты: 1.2E0, 0.12e1. Отметим, что обе предыдущие записи изображают одно и то же число 1.2.
По умолчанию вещественная константа принадлежит к типу double . Чтобы обозначить, что константа на самом деле float , нужно добавить символ f или F после числа: 2.7f. Символ l или L означает, что записанное число относится к типу long double .
const float pi_f = 3.14f; double pi_d = 3.1415; long double pi_l = 3.1415L;
Для вещественных чисел определены все стандартные арифметические операции сложения (+), вычитания (-), умножения (*), деления (/) и изменения знака (-). В отличие от целых чисел, операция нахождения остатка от деления для вещественных чисел не определена. Аналогично, все битовые операции и сдвиги к вещественным числам неприменимы; они работают только с целыми числами. Примеры операций:
* pi; (x – e) / 4.0
Вещественные числа можно сравнивать на равенство (==), неравенство (!=), больше (), меньше (), больше или равно (=) и меньше или равно (=). В результате операции сравнения получается логическое значение истина или ложь.
Если арифметическая операция применяется к двум вещественным числам разных типов, то менее точное число преобразуется в более точное, т.е. float преобразуется в double и double преобразуется в long double . Очевидно, что такое преобразование всегда можно выполнить без потери точности.
Если вторым операндом в операции с вещественным числом является целое число, то целое число преобразуется в вещественное представление.
Хотя любую целую величину можно представить в виде вещественного числа, при таком преобразовании возможна потеря точности (для больших чисел).
Переопределение операций
В языке Си++ можно сделать так, что класс будет практически неотличим от предопределенных встроенных типов при использовании в выражениях. Для класса можно определить операции сложения, умножения и т.д. пользуясь стандартной записью таких операций, т.е. x + y. В языке Си++ считается, что подобная запись - это также вызов метода с именем operator+ того класса, к которому принадлежит переменная x. Перепишем определение класса Complex:
// определение класса комплексных чисел class Complex { public: int real; // вещественная часть int imaginary; // мнимая часть // прибавить комплексное число Complex operator+(const Complex x) const; };
Вместо метода Add появился метод operator+. Изменилось и его определение. Во-первых, этот метод возвращает значение типа Complex (операция сложения в результате дает новое значение того же типа, что и типы операндов). Во-вторых, перед аргументом метода появилось ключевое слово const. Это слово обозначает, что при выполнении данного метода аргумент изменяться не будет. Также const появилось после объявления метода. Второе ключевое слово const означает, что объект, выполняющий метод, не будет изменен. При выполнении операции сложения x + y над двумя величинами x и y сами эти величины не изменяются. Теперь запишем определение операции сложения:
Complex Complex::operator+(const Complex x) const { Complex result; result.real = real + x.real; result.imaginary = imaginary + x.imaginary; return result; }
Подписи методов и необязательные аргументы
Как и при объявлении функций, язык Си++ допускает определение в одном классе нескольких методов с одним и тем же именем, но разными типами и количеством аргументов. (Определение методов или атрибутов с одинаковыми именами в разных классах не вызывает проблем, поскольку пространства имен разных классов не пересекаются).
// определение класса комплексных чисел class Complex { public: int real; // вещественная часть int imaginary; // мнимая часть // прибавить комплексное число Complex operator+(const Complex x) const; // прибавить целое число Complex operator+(long x) const; };
В следующем примере вначале складываются два комплексных числа, и вызывается первая операция +. Затем к комплексному числу прибавляется целое число, и тогда выполняется вторая операция сложения.
Complex c1; Complex c2; long x; c1 + c2; c2 + x;
Аналогично можно задавать значения аргументов методов по умолчанию. Более подробное описание можно найти в лекции 5.
Понятие класса
До сих пор мы говорили о встроенных типах, т.е. типах, определенных в самом языке. Классы - это типы, определенные в конкретной программе. Определение класса включает в себя описание, из каких составных частей или атрибутов он состоит и какие операции определены для класса.
Предположим, в программе необходимо оперировать комплексными числами. Комплексные числа состоят из вещественной и мнимой частей, и с ними можно выполнять арифметические операции.
class Complex { public: int real; // вещественная часть int imaginary; // мнимая часть void Add(Complex x); // прибавить комплексное число };
Приведенный выше пример - упрощенное определение класса Complex, представляющее комплексное число. Комплексное число состоит из вещественной части - целого числа real и мнимой части, которая представлена целым числом imaginary. real и imaginary - это атрибуты класса. Для класса Complex определена одна операция или метод - Add.
Определив класс, мы можем создать переменную типа Complex:
Complex number;
Переменная с именем number содержит значение типа Complex, то есть содержит объект класса Complex. Имея объект, мы можем установить значения атрибутов объекта:
number.real = 1; number.imaginary = 2;
Операция "." обозначает обращение к атрибуту объекта. Создав еще один объект класса Complex, мы можем прибавить его к первому:
Complex num2; number.Add(num2);
Как можно заметить, метод Add выполняется с объектом. Имя объекта (или переменной, содержащей объект, что, в сущности, одно и то же), в данном случае, number, записано первым. Через точку записано имя метода - Add с аргументом - значением другого объекта класса Complex, который прибавляется к number. Методы часто называются сообщениями. Но чтобы послать сообщение, необходим получатель. Таким образом, объекту number посылается сообщение Add с аргументом num2. Объект number принимает это сообщение и складывает свое значение со значением аргумента сообщения.
Адресная арифметика
С указателями можно выполнять не только операции присваивания и обращения по адресу, но и ряд арифметических операций. Прежде всего, указатели одного и того же типа можно сравнивать с помощью стандартных операций сравнения. При этом сравниваются значения указателей, а не значения величин, на которые данные указатели ссылаются. Так, в приведенном ниже примере результат первой операции сравнения будет ложным:
int x = 10; int y = 10; int* xptr = x; int* yptr = y; // сравниваем указатели if (xptr == yptr) { cout "Указатели равны" endl; } else { cout "Указатели не равны" endl; } // сравниваем значения, на которые указывают // указатели if (*xptr == *yptr) { cout "Значения равны" endl; } else { cout "Значения неравны" endl; }
Однако результат второй операции сравнения будет истинным, поскольку переменные x и y имеют одно и то же значение.
Кроме того, над указателями можно выполнять ограниченный набор арифметических операций. К указателю можно прибавить целое число или вычесть из него целое число. Результатом прибавления к указателю единицы является адрес следующей величины типа, на который ссылается указатель, в памяти. Поясним это на рисунке. Пусть xPtr – указатель на целое число типа long, а cp – указатель на тип char. Начиная с адреса 1000, в памяти расположены два целых числа. Адрес второго — 1004 (в большинстве реализаций Си++ под тип long выделяется четыре байта). Начиная с адреса 2000, в памяти расположены объекты типа char.

8.2. Адресная арифметика.
Размер памяти, выделяемой для числа типа long и для char, различен. Поэтому адрес при увеличении xPtr и cp тоже изменяется по-разному. Однако и в том, и в другом случае увеличение указателя на единицу означает переход к следующей в памяти величине того же типа. Прибавление или вычитание любого целого числа работает по тому же принципу, что и увеличение на единицу. Указатель сдвигается вперед (при прибавлении положительного числа) или назад (при вычитании положительного числа) на соответствующее количество объектов того типа, на который показывает указатель. Вообще говоря, неважно, объекты какого типа на самом деле находятся в памяти — адрес просто увеличивается или уменьшается на необходимую величину. На самом деле значение указателя ptr всегда изменяется на число, кратное sizeof(*ptr).
Указатели одного и того же типа можно друг из друга вычитать. Разность указателей показывает, сколько объектов соответствующего типа может поместиться между указанными адресами.
Бестиповый указатель
Особым случаем указателей является бестиповый указатель. Ключевое слово void используется для того, чтобы показать, что указатель означает просто адрес памяти, независимо от типа величины, находящейся по этому адресу:
void* ptr;
Для указателя на тип void не определена операция -, не определена операция обращения по адресу *, не определена адресная арифметика. Использование бестиповых указателей ограничено работой с памятью при использовании ряда системных функций, передачей адресов в функции, написанные на языках программирования более низкого уровня, например на ассемблере.
В программе на языке Си++ бестиповый указатель может применяться там, где адрес интерпретируется по-разному, в зависимости от каких-либо динамически вычисляемых условий. Например, приведенная ниже функция будет печатать целое число, содержащееся в одном, двух или четырех байтах, расположенных по передаваемому адресу:
void printbytes(void* ptr, int nbytes) { if (nbytes == 1) { char* cptr = (char*)ptr; cout *cptr; } else if (nbytes == 2) { short* sptr = (short*)ptr; cout *sptr; } else if (nbytes == 4) { long* lptr = (long*)ptr; cout *lptr; } else { cout "Неверное значение аргумента"; } }
В примере используется операция явного преобразования типа. Имя типа, заключенное в круглые скобки, стоящее перед выражением, преобразует значение этого выражения к указанному типу. Разумеется, эта операция может применяться к любым указателям.
Битовые поля
В структуре можно определить размеры атрибута с точностью до бита. Традиционно структуры используются в системном программировании для описания регистров аппаратуры. В них каждый бит имеет свое значение. Не менее важной является возможность экономии памяти – ведь минимальный тип атрибута структуры это байт (char), который занимает 8 битов. До сих пор, несмотря на мегабайты и даже гигабайты оперативной памяти, используемые в современных компьютерах, существует немало задач, где каждый бит на счету.
Если после описания атрибута структуры поставить двоеточие и затем целое число, то это число задает количество битов, выделенных под данный атрибут структуры. Такие атрибуты называют битовыми полями. Следующая структура хранит в компактной форме дату и время дня с точностью до секунды.
struct TimeAndDate { unsigned hours :5; // часы от 0 до 24 unsigned mins :6; // минуты unsigned secs :6; // секунды от 0 до 60 unsigned weekDay :3; // день недели unsigned monthDay :6; // день месяца от 1 до 31 unsigned month :5; // месяц от 1 до 12 unsigned year :8; // год от 0 до 100 };
Одна структура TimeAndDate требует всего 39 битов, т.е. 5 байтов (один байт — 8 битов). Если бы мы использовали для каждого атрибута этой структуры тип char, нам бы потребовалось 7 байтов.
Массивы
Массив – это коллекция нескольких величин одного и того же типа. Простейшим примером массива может служить набор из двенадцати целых чисел, соответствующих числу дней в каждом календарном месяце:
int days[12]; days[0] = 31; // январь days[1] = 28; // февраль days[2] = 31; // март days[3] = 30; // апрель days[4] = 31; // май days[5] = 30; // июнь days[6] = 31; // июль days[7] = 31; // август days[8] = 30; // сентябрь days[9] = 31; // октябрь days[10] = 30; // ноябрь days[11] = 31; // декабрь
В первой строчке мы объявили массив из 12 элементов типа int и дали ему имя days. Остальные строки примера – присваивания значений элементам массива. Для того, чтобы обратиться к определенному элементу массива, используют операцию индексации []. Как видно из примера, первый элемент массива имеет индекс 0, соответственно, последний – 11.
При объявлении массива его размер должен быть известен в момент компиляции, поэтому в качестве размера можно указывать только целую константу. При обращении же к элементу массива в роли значения индекса может выступать любая переменная или выражение, которое вычисляется во время выполнения программы и преобразуется к целому значению.
Предположим, мы хотим распечатать все элементы массива days. Для этого удобно воспользоваться циклом for.
for (int i = 0; i 12; i++) { cout days[i]; }
Следует отметить, что при выполнении программы границы массива не контролируются. Если мы ошиблись и вместо 12 в приведенном выше цикле написали 13, то компилятор не выдаст ошибку. При выполнении программа попытается напечатать 13-е число. Что при этом случится, вообще говоря, не определено. Быть может, произойдет сбой программы. Более вероятно, что будет напечатано какое-то случайное 13-е число. Выход индексов за границы массива – довольно распространенная ошибка, которую иногда очень трудно обнаружить. В дальнейшем при изучении классов мы рассмотрим, как можно переопределить операцию [] и добавить контроль за индексами.
Отсутствие контроля индексов налагает на программиста большую ответственность. С другой стороны, индексация – настолько часто используемая операция, что наличие контроля, несомненно, повлияло бы на производительность программ.
Рассмотрим еще один пример. Предположим, что имеется массив из 100 целых чисел, и его необходимо отсортировать, т.е. расположить в порядке возрастания. Сортировка методом "пузырька" – наиболее простая и распространенная – будет выглядеть следующим образом:
int array[100]; . . . for (int i = 0; i 99; i++ ) { for (int j = i + 1; j 100; j++) { if (array[j] array[i] ) { int tmp = array[j]; array[j] = array[i]; array[i] = tmp; } } }
В приведенных примерах у массивов имеется только один индекс. Такие одномерные массивы часто называются векторами. Имеется возможность определить массивы с несколькими индексами или размерностями. Например, объявление
int m[10][5];
представляет матрицу целых чисел размером 10 на 5. По-другому интерпретировать приведенное выше объявление можно как массив из 10 элементов, каждый из которых – вектор целых чисел длиной 5. Общее количество целых чисел в массиве m равно 50.
Обращение к элементам многомерных массивов аналогично обращению к элементам векторов: m[1][2] обращается к третьему элементу второй строки матрицы m.
Количество размерностей в массиве может быть произвольным. Как и в случае с вектором, при объявлении многомерного массива все его размеры должны быть заданы константами.
При объявлении массива можно присвоить начальные значения его элементам (инициализировать массив). Для вектора это будет выглядеть следующим образом:
int days[12] = { 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 };
При инициализации многомерных массивов каждая размерность должна быть заключена в фигурные скобки:
double temp[2][3] = { { 3.2, 3.3, 3.4 }, { 4.1, 3.9, 3.9 } };
Интересной особенностью инициализации многомерных массивов является возможность не задавать размеры всех измерений массива, кроме самого последнего. Приведенный выше пример можно переписать так:
double temp[][3] = { { 3.2, 3.3, 3.4 }, { 4.1, 3.9, 3.9 } }; // Вычислить размер пропущенной размерности const int size_first = sizeof (temp) / sizeof (double[3]);
Объединения
Особым видом структур данных является объединение. Определение объединения напоминает определение структуры, только вместо ключевого слова struct используется union:
union number { short sx; long lx; double dx; };
В отличие от структуры, все атрибуты объединения располагаются по одному адресу. Под объединение выделяется столько памяти, сколько нужно для хранения наибольшего атрибута объединения. Объединения применяются в тех случаях, когда в один момент времени используется только один атрибут объединения и, прежде всего, для экономии памяти. Предположим, нам нужно определить структуру, которая хранит "универсальное" число, т.е. число одного из предопределенных типов, и признак типа. Это можно сделать следующим образом:
struct Value { enum NumberType { ShortType, LongType, DoubleType }; NumberType type; short sx; // если type равен ShortType long lx; // если type равен LongType double dx; // если type равен DoubleType };
Атрибут type содержит тип хранимого числа, а соответствующий атрибут структуры – значение числа.
Value shortVal; shortVal.type = Value::ShortType; shortVal.sx = 15;
Хотя память выделяется под все три атрибута sx, lx и dx, реально используется только один из них. Сэкономить память можно, используя объединение:
struct Value { enum NumberType { ShortType, LongType, DoubleType }; NumberType type; union number { short sx; // если type равен ShortType long lx; // если type равен LongType double dx; // если type равен DoubleType } val; };
Теперь память выделена только для максимального из этих трех атрибутов (в данном случае dx). Однако и обращаться с объединением надо осторожно. Поскольку все три атрибута делят одну и ту же область памяти, изменение одного из них означает изменение всех остальных. На рисунке поясняется выделение памяти под объединение. В обоих случаях мы предполагаем, что структура расположена по адресу 1000. Объединение располагает все три своих атрибута по одному и тому же адресу.

8.1. Использование памяти в объединениях.
Строки и литералы
Для того чтобы работать с текстом, в языке Си++ не существует особого встроенного типа данных. Текст представляется в виде последовательности знаков (байтов), заканчивающейся нулевым байтом. Иногда такое представление называют Си-строки, поскольку оно появилось в языке Си. Кроме того, в Си++ можно создать классы для более удобной работы с текстами (готовые классы для представления строк имеются в стандартной библиотеке шаблонов).
Строки представляются в виде массива байтов:
char string[20]; string[0] = 'H'; string[1] = 'e'; string[2] = 'l'; string[3] = 'l'; string[4] = 'o'; string[5] = 0;
В массиве string записана строка "Hello". При этом мы использовали только 6 из 20 элементов массива.
Для записи строковых констант в программе используются литералы. Литерал – это последовательность знаков, заключенная в двойные кавычки:
"Это строка" "0123456789" "*"
Заметим, что символ, заключенный в двойные кавычки, отличается от символа, заключенного в апострофы. Литерал "*" обозначает два байта: первый байт содержит символ звездочки, второй байт содержит ноль. Константа '*' обозначает один байт, содержащий знак звездочки.
С помощью литералов можно инициализировать массивы:
char alldigits[] = "0123456789";
Размер массива явно не задан, он определяется исходя из размера инициализирующего его литерала, в данном случае 11 (10 символов плюс нулевой байт).
При работе со строками особенно часто используется связь между массивами и указателями. Значение литерала – это массив неизменяемых байтов нужного размера. Строковый литерал может быть присвоен указателю на char:
const char* message = "Сообщение программы";
Значение литерала – это адрес его первого байта, указатель на начало строки. В следующем примере функция CopyString копирует первую строку во вторую:
void CopyString(char* src, char* dst) { while (*dst++ = *src++) ; *dst = 0; } int main() { char first[] = "Первая строка"; char second[100]; CopyString(first, second); return 1; }
Указатель на байт (тип char*) указывает на начало строки. Предположим, нам нужно подсчитать количество цифр в строке, на которую показывает указатель str:
#include ctype.h int count = 0; while (*str != 0) { // признак конца строки – ноль
if (isdigit(*str++)) // проверить байт, на который
count++; // указывает str, и сдвинуть // указатель на следующий байт }
При выходе из цикла while переменная count содержит количество цифр в строке str, а сам указатель str указывает на конец строки – нулевой байт. Чтобы проверить, является ли текущий символ цифрой, используется функция isdigit. Это одна из многих стандартных функций языка, предназначенных для работы с символами и строками.
С помощью функций стандартной библиотеки языка реализованы многие часто используемые операции над символьными строками. В большинстве своем в качестве строк они воспринимают указатели. Приведем ряд наиболее употребительных. Прежде чем использовать эти указатели в программе, нужно подключить их описания с помощью операторов #include string.h и #include ctype.h.
char* strcpy(char* target, const char* source);
Копировать строку source по адресу target, включая завершающий нулевой байт. Функция предполагает, что памяти, выделенной по адресу target, достаточно для копируемой строки. В качестве результата функция возвращает адрес первой строки.
char* strcat(char* target, const char* source);
Присоединить вторую строку с конца первой, включая завершающий нулевой байт. На место завершающего нулевого байта первой строки переписывается первый символ второй строки. В результате по адресу target получается строка, образованная слиянием первой со второй. В качестве результата функция возвращает адрес первой строки.
int strcmp(const char* string1, const char* string2);
Сравнить две строки в лексикографическом порядке (по алфавиту). Если первая строка должна стоять по алфавиту раньше, чем вторая, то результат функции меньше нуля, если позже – больше нуля, и ноль, если две строки равны.
size_t strlen(const char* string);
Определить длину строки в байтах, не считая завершающего нулевого байта.
В следующем примере, использующем приведенные функции, в массиве result будет образована строка "1 января 1998 года, 12 часов":
char result[100]; char* date = "1 января 1998 года"; char* time = "12 часов"; strcpy(result, date); strcat(result, ", "); strcat(result, time);
Как видно из этого примера, литералы можно непосредственно использовать в выражениях.
Определить массив строк можно с помощью следующего объявления:
char* StrArray[5] = { "one", "two", "three", "four", "five" };
Структуры
Структуры – это не что иное, как классы, у которых разрешен доступ ко всем их элементам (доступ к определенным атрибутам класса может быть ограничен, о чем мы узнаем в лекции 11). Пример структуры:
struct Record { int number; char name[20]; };
Так же, как и для классов, операция "." обозначает обращение к элементу структуры.
В отличие от классов, можно определить переменную-структуру без определения отдельного типа:
struct { double x; double y; } coord;
Обратиться к атрибутам переменной coord можно coord.x и coord.y.
Связь между массивами и указателями
Между указателями и массивами существует определенная связь. Предположим, имеется массив из 100 целых чисел. Запишем двумя способами программу суммирования элементов этого массива:
long array[100]; long sum = 0; for (int i = 0; i 100; i++) sum += array[i];
То же самое можно сделать с помощью указателей:
long array[100]; long sum = 0; for (long* ptr = array[0]; ptr array[99] + 1; ptr++) sum += *ptr;
Элементы массива расположены в памяти последовательно, и увеличение указателя на единицу означает смещение к следующему элементу массива. Упоминание имени массива без индексов преобразуется в адрес его первого элемента:
for (long* ptr = array; ptr array[99] + 1; ptr++) sum += *ptr;
Хотя смешивать указатели и массивы можно, мы бы не стали рекомендовать такой стиль, особенно начинающим программистам.
При использовании многомерных массивов указатели позволяют обращаться к срезам или подмассивам. Если мы объявим трехмерный массив exmpl:
long exmpl[5][6][7]
то выражение вида exmpl[1][1][2] – это целое число, exmpl[1][1] – вектор целых чисел (адрес первого элемента вектора, т.е. имеет тип *long), exmpl[1] – двухмерная матрица или указатель на вектор (тип (*long)[7]). Таким образом, задавая не все индексы массива, мы получаем указатели на массивы меньшей размерности.
Указатели
Указатель – это производный тип, который представляет собой адрес какого-либо значения. В языке Си++ используется понятие адреса переменных. Работа с адресами досталась Си++ в наследство от языка Си. Предположим, что в программе определена переменная типа int:
int x;
Можно определить переменную типа "указатель" на целое число:
int* xptr;
и присвоить переменной xptr адрес переменной x:
xptr = x;
Операция , примененная к переменной, – это операция взятия адреса. Операция *, примененная к адресу, – это операция обращения по адресу. Таким образом, два оператора эквивалентны:
int y = x; // присвоить переменной y значение x int y = *xptr; // присвоить переменной y значение, // находящееся по адресу xptr
С помощью операции обращения по адресу можно записывать значения:
*xptr = 10; // записать число 10 по адресу xptr
После выполнения этого оператора значение переменной x станет равным 10, поскольку xptr указывает на переменную x.
Указатель – это не просто адрес, а адрес величины определенного типа. Указатель xptr – адрес целой величины. Определить адреса величин других типов можно следующим образом:
unsigned long* lPtr; // указатель на целое число без знака
char* cp; // указатель на байт
Complex* p; // указатель на объект класса Complex
Если указатель ссылается на объект некоторого класса, то операция обращения к атрибуту класса вместо точки обозначается "-", например p-real. Если вспомнить один из предыдущих примеров:
void Complex::Add(Complex x) { this-real = this-real + x.real; this-imaginary = this-imaginary + x.imaginary; }
то this – это указатель на текущий объект, т.е. объект, который выполняет метод Add. Запись this- означает обращение к атрибуту текущего объекта.
Можно определить указатель на любой тип, в том числе на функцию или метод класса. Если имеется несколько функций одного и того же типа:
int foo(long x); int bar(long x);
можно определить переменную типа указатель на функцию и вызывать эти функции не напрямую, а косвенно, через указатель:
int (*functptr)(long x); functptr = foo; (*functptr)(2); functptr = bar; (*functptr)(4);
Для чего нужны указатели? Указатели появились, прежде всего, для нужд системного программирования. Поскольку язык Си предназначался для "низкоуровневого" программирования, на нем нужно было обращаться, например, к регистрам устройств. У этих регистров вполне определенные адреса, т.е. необходимо было прочитать или записать значение по определенному адресу. Благодаря механизму указателей, такие операции не требуют никаких дополнительных средств языка.
int* hardwareRegiste =0x80000; *hardwareRegiste =12;
Однако использование указателей нуждами системного программирования не ограничивается. Указатели позволяют существенно упростить и ускорить ряд операций. Предположим, в программе имеется область памяти для хранения промежуточных результатов вычислений. Эту область памяти используют разные модули программы. Вместо того, чтобы каждый раз при обращении к модулю копировать эту область памяти, мы можем передавать указатель в качестве аргумента вызова функции, тем самым упрощая и ускоряя вычисления.
struct TempResults { double x1; double x2; } tempArea; // Функция calc возвращает истину, если // вычисления были успешны, и ложь – при // наличии ошибки. Вычисленные результаты // записываются на место аргументов по // адресу, переданному в указателе trPtr bool calc(TempResults* trPtr) { // вычисления if (noerrors) { trPtr-x1 = res1; trPtr-x2 = res2; return true; } else { return false; } } void fun1(void) { . . . TempResults tr; tr.x1 = 3.4; tr.x2 = 5.4; if (calc(tr) == false) { // обработка ошибки } . . . }
В приведенном примере проиллюстрированы сразу две возможности использования указателей: передача адреса общей памяти и возможность функции иметь более одного значения в качестве результата. Структура TempResults используется для хранения данных. Вместо того чтобы передавать эти данные по отдельности, в функцию calc передается указатель на структуру. Таким образом достигаются две цели: большая наглядность и большая эффективность (не надо копировать элементы структуры по одному). Функция calc возвращает булево значение – признак успешного завершения вычислений. Сами же результаты вычислений записываются в структуру, указатель на которую передан в качестве аргумента.
Упомянутые примеры использования указателей никак не связаны с объектно-ориентированным программированием. Казалось бы, объектно-ориентированное программирование должно уменьшить зависимость от низкоуровневых конструкций типа указателей. На самом деле программирование с классами нисколько не уменьшило потребность в указателях, и даже наоборот, нашло им дополнительное применение, о чем мы будем рассказывать по ходу изложения.
Автоматические переменные
Самый простой метод – это объявление переменных внутри функций. Если переменная объявлена внутри функции, каждый раз, когда функция вызывается, под переменную автоматически отводится память. Когда функция завершается, память, занимаемая переменными, освобождается. Такие переменные называют автоматическими.
При создании автоматических переменных они никак не инициализируются, т.е. значение автоматической переменной сразу после ее создания не определено, и нельзя предсказать, каким будет это значение. Соответственно, перед использованием автоматических переменных необходимо либо явно инициализировать их, либо присвоить им какое-либо значение.
int funct() { double f; // значение f не определено f = 1.2; // теперь значение f определено // явная инициализация автоматической // переменной bool result = true; . . . }
Аналогично автоматическим переменным, объявленным внутри функции, автоматические переменные, объявленные внутри блока (последовательности операторов, заключенных в фигурные скобки) создаются при входе в блок и уничтожаются при выходе из блока.
Замечание. Распространенной ошибкой является использование адреса автоматической переменной после выхода из функции. Конструкция типа:
int* func() { int x; . . . return х; }
дает непредсказуемый результат.
Распределение памяти при передаче аргументов функции
Рассказывая о функциях, мы отметили, что у функций (как и у методов классов) есть аргументы, фактические значения которых передаются при вызове функции.
Рассмотрим более подробно метод Add класса Complex. Изменим его немного, так, чтобы он вместо изменения состояния объекта возвращал результат операции сложения:
Complex Complex::Add(Complex x) { Complex result; result.real = real + x.real; result.imaginary = imaginary + x.imaginary; return result; }
При вызове этого метода
Complex n1; Complex n2; . . . Complex n3 = n1.Add(n2);
значение переменной n2 передается в качестве аргумента. Компилятор создает временную переменную типа Complex, копирует в нее значение n2 и передает эту переменную в метод Add. Такая передача аргумента называется передачей по значению. У передачи аргументов по значению имеется два свойства. Во-первых, эта операция не очень эффективна, особенно если объект сложный и требует большого объема памяти или же если создание объекта сопряжено с выполнением сложных действий (о конструкторах объектов будет рассказано в лекции 12). Во-вторых, изменения аргумента функции не сохраняются. Если бы метод Add был бы определен как
Complex Complex::Add(Complex x) { Complex result; x.imaginary = 0; // изменение аргумента метода result.real = real + x.real; result.imaginary = imaginary + x.imaginary; return result; }
то при вызове n3 = n1.Add(n2) результат был бы, конечно, другой, но значение переменной n2 не изменилось бы. Хотя в данном примере изменяется значение аргумента метода Add, этот аргумент – лишь копия объекта n2, а не сам объект. По завершении выполнения метода Add его аргументы просто уничтожаются, и первоначальные значения фактических параметров сохраняются.
При возврате результата функции выполняются те же действия, т.е. создается временная переменная, в которую копируется результат, и уже затем значение временной переменной копируется в переменную n3. Временные переменные потому и называют временными, что компилятор сам создает их на время выполнения метода и сам их уничтожает.
Другим способом передачи аргументов является передача по ссылке. Если изменить описание метода Add на
Complex Complex::Add(Complex x) { Complex result; result.real = real + x.real; result.imaginary = imaginary + x.imaginary; return result; }
то при вызове n3 = n1.Add(n2) компилятор будет создавать ссылку на переменную n2 и передавать ее методу Add. В большинстве случаев это намного эффективнее, так как для ссылки требуется немного памяти и создать ее проще. Однако мы получим нежелательный в данном случае эффект. Метод
Complex Complex::Add(Complex x) { Complex result; x.imaginary = 0; // изменение значения // по переданной ссылке result.real = real + x.real; result.imaginary = imaginary + x.imaginary; return result; }
изменит значение переменной n2. Операция Add не предусматривает изменения собственных операндов. Чтобы избежать ошибок, лучше записать аргумент с описателем const, который определяет соответствующую переменную как неизменяемую.
Complex::Add(const Complex x)
В таком случае попытка изменить значение аргумента будет обнаружена на этапе компиляции, и компилятор выдаст ошибку. Передачей аргумента по неконстантной ссылке можно воспользоваться в том случае, когда функция действительно должна изменить свой аргумент. Например, метод Coord класса Figure записывает координаты некой фигуры в свои аргументы:
void Figure::Coord(int x, int y) { x = coordx; y = coordy; }
При вызове
int cx, cy; Figure fig; . . . fig.Coord(cx, cy);
переменным cx и cy будет присвоено значение координат фигуры fig.
Вернемся к методу Add и попытаемся оптимизировать передачу вычисленного значения. Простое на первый взгляд решение возвращать ссылку на результат не работает:
Complex Complex::Add(const Complex x) { Complex result; result.real = real + x.real; result.imaginary = imaginary + x.imaginary; return result; }
При выходе из метода автоматическая переменная result уничтожается, и память, выделенная для нее, освобождается. Поэтому результат Add – ссылка на несуществующую память. Результат подобных действий непредсказуем. Иногда программа будет работать как ни в чем не бывало, иногда может произойти сбой, иногда результат будет испорчен. Однако возвращение результата по ссылке возможно, если объект, на который эта ссылка ссылается, не уничтожается после выхода из функции или метода. Если метод Add прибавляет значение аргумента к текущему значению объекта и возвращает новое значение в качестве результата, то его можно записать:
Complex Complex::Add(Complex x) { Complex result; result.real = real + x.real; result.imaginary = imaginary + x.imaginary; return result; }
то при вызове n3 = n1.Add(n2) компилятор будет создавать ссылку на переменную n2 и передавать ее методу Add. В большинстве случаев это намного эффективнее, так как для ссылки требуется немного памяти и создать ее проще. Однако мы получим нежелательный в данном случае эффект. Метод
Complex Complex::Add(Complex x) { Complex result; x.imaginary = 0; // изменение значения // по переданной ссылке result.real = real + x.real; result.imaginary = imaginary + x.imaginary; return result; }
изменит значение переменной n2. Операция Add не предусматривает изменения собственных операндов. Чтобы избежать ошибок, лучше записать аргумент с описателем const, который определяет соответствующую переменную как неизменяемую.
Complex::Add(const Complex x)
В таком случае попытка изменить значение аргумента будет обнаружена на этапе компиляции, и компилятор выдаст ошибку. Передачей аргумента по неконстантной ссылке можно воспользоваться в том случае, когда функция действительно должна изменить свой аргумент. Например, метод Coord класса Figure записывает координаты некой фигуры в свои аргументы:
void Figure::Coord(int x, int y) { x = coordx; y = coordy; }
При вызове
int cx, cy; Figure fig; . . . fig.Coord(cx, cy);
переменным cx и cy будет присвоено значение координат фигуры fig.
Вернемся к методу Add и попытаемся оптимизировать передачу вычисленного значения. Простое на первый взгляд решение возвращать ссылку на результат не работает:
Complex Complex::Add(const Complex x) { Complex result; result.real = real + x.real; result.imaginary = imaginary + x.imaginary; return result; }
При выходе из метода автоматическая переменная result уничтожается, и память, выделенная для нее, освобождается. Поэтому результат Add – ссылка на несуществующую память. Результат подобных действий непредсказуем. Иногда программа будет работать как ни в чем не бывало, иногда может произойти сбой, иногда результат будет испорчен. Однако возвращение результата по ссылке возможно, если объект, на который эта ссылка ссылается, не уничтожается после выхода из функции или метода. Если метод Add прибавляет значение аргумента к текущему значению объекта и возвращает новое значение в качестве результата, то его можно записать:
Рекомендации по использованию указателей и динамического распределения памяти
Указатели и динамическое распределение памяти – очень мощные средства языка. С их помощью можно разрабатывать гибкие и весьма эффективные программы. В частности, одна из областей применения Си++ – системное программирование – практически не могла бы существовать без возможности работы с указателями. Однако возможности, которые получает программист при работе с указателями, накладывают на него и большую ответственность. Наибольшее количество ошибок в программу вносится именно при работе с указателями. Как правило, эти ошибки являются наиболее трудными для обнаружения и исправления.
Приведем несколько примеров.
Использование неверного адреса в операции delete. Результат такой операции непредсказуем. Вполне возможно, что сама операция пройдет успешно, однако внутренняя структура памяти будет испорчена, что приведет либо к ошибке в следующей операции new, либо к порче какой-нибудь информации.
Пропущенное освобождение памяти, т.е. программа многократно выделяет память под данные, но "забывает" ее освобождать. Такие ошибки называют утечками памяти. Во-первых, программа использует ненужную ей память, тем самым понижая производительность. Кроме того, вполне возможно, что в 99 случаях из 100 программа будет успешно выполнена. Однако если потеря памяти окажется слишком большой, программе не хватит памяти под какие-нибудь данные и, соответственно, произойдет сбой.
Запись по неверному адресу. Скорее всего, будут испорчены какие-либо данные. Как проявится такая ошибка – неверным результатом, сбоем программы или иным образом – предсказать трудно
Примеры ошибок можно приводить бесконечно. Общие их черты, обуславливающие сложность обнаружения, это, во-первых, непредсказуемость результата и, во-вторых, проявление не в момент совершения ошибки, а позже, быть может, в том месте программы, которое само по себе не содержит ошибки (неверная операция delete – сбой в последующей операции new, запись по неверному адресу – использование испорченных данных в другой части программы и т.п.).
Отнюдь не призывая отказаться от применения указателей (впрочем, в Си++ это практически невозможно), мы хотим подчеркнуть, что их использование требует внимания и дисциплины. Несколько общих рекомендаций.
Используйте указатели и динамическое распределение памяти только там, где это действительно необходимо. Проверьте, можно ли выделить память статически или использовать автоматическую переменную. Старайтесь локализовать распределение памяти. Если какой-либо метод выделяет память (в особенности под временные данные), он же и должен ее освободить. Там, где это возможно, вместо указателей используйте ссылки.Проверяйте программы с помощью специальных средств контроля памяти (Purify компании Rational, Bounce Checker компании Nu-Mega и т.д.)
Ссылки
Ссылка – это еще одно имя переменной. Если имеется какая-либо переменная, например
Complex x;
то можно определить ссылку на переменную x как
Complex y = x;
и тогда x и y обозначают одну и ту же величину. Если выполнены операторы
x.real = 1; x.imaginary = 2;
то y.real равно 1 и y.imaginary равно 2. Фактически, ссылка – это адрес переменной (поэтому при определении ссылки используется символ -- знак операции взятия адреса), и в этом смысле она сходна с указателем, однако у ссылок есть свои особенности.
Во-первых, определяя переменную типа ссылки, ее необходимо инициализировать, указав, на какую переменную она ссылается. Нельзя определить ссылку
int xref;
можно только
int xref = x;
Во-вторых, нельзя переопределить ссылку, т.е. изменить на какой объект она ссылается. Если после определения ссылки xref мы выполним присваивание
xref = y;
то выполнится присваивание значения переменной y той переменной, на которую ссылается xref. Ссылка xref по-прежнему будет ссылаться на x. В результате выполнения следующего фрагмента программы:
int x = 10; int y = 20; int xref = x; xref = y; x += 2; cout "x = " x endl; cout "y = " y endl; cout "xref = " xref endl;
будет выведено:
x = 22 y = 20 xref = 22
В-третьих, синтаксически обращение к ссылке аналогично обращению к переменной. Если для обращения к атрибуту объекта, на который ссылается указатель, применяется операция -, то для подобной же операции со ссылкой применяется точка ".".
Complex a; Complex* aptr = a; Complex aref = a; aptr-real = 1; aref.imaginary = 2;
Как и указатель, ссылка сама по себе не имеет значения.Ссылка должна на что-то ссылаться, тогда как указатель должен на что-то указывать.
Статические переменные
Другой способ выделения памяти – статический
Если переменная определена вне функции, память для нее отводится статически, один раз в начале выполнения программы, и переменная уничтожается только тогда, когда выполнение программы завершается. Можно статически выделить память и под переменную, определенную внутри функции или блока. Для этого нужно использовать ключевое слово static в его определении:
double globalMax; // переменная определена вне функции void func(int x) { static bool visited = false; if (!visited) { . . . // инициализация visited = true; } . . . }
В данном примере переменная visited создается в начале выполнения программы. Ее начальное значение – false. При первом вызове функции func условие в операторе if будет истинным, выполнится инициализация, и переменной visited будет присвоено значение true. Поскольку статическая переменная создается только один раз, ее значения между вызовами функции сохраняются. При втором и последующих вызовах функции func инициализация производиться не будет.
Если бы переменная visited не была объявлена static, то инициализация происходила бы при каждом вызове функции.
Выделение памяти под строки
В следующем фрагменте программы мы динамически выделяем память под строку переменной длины и копируем туда исходную строку
// стандартная функция strlen подсчитывает // количество символов в строке int length = strlen(src_str); // выделить память и добавить один байт // для завершающего нулевого байта char* buffer = new char[length + 1]; strcpy(buffer, src_str); // копирование строки
Операция new возвращает адрес выделенной памяти. Однако нет никаких гарантий, что new обязательно завершится успешно. Объем оперативной памяти ограничен, и может случиться так, что найти еще один участок свободной памяти будет невозможно. В таком случае new возвращает нулевой указатель (адрес 0). Результат new необходимо проверять:
char* newstr; newstr = new char[length]; if (newstr == NULL) { // проверить результат // обработка ошибок } // память выделена успешно
